Забудьте о том, что ИИ-агенты просто хранят информацию. Последний шаг Amazon с AgentCore Memory направлен на то, чтобы они могли её действительно находить и, что важно, сохранять в безопасности. Это не абстрактная инженерная задача; это суровая реальность создания ИИ, который может осмысленно учиться и взаимодействовать, не превращаясь в решето с утечками или свалку данных.
По сути, они перестраивают способ организации памяти ИИ-агентов. Думайте об этом не как о забытом дневнике, а скорее как о гипер-организованном картотечном шкафе. Это важно, потому что если ИИ не может вспомнить правильный контекст, он бесполезен. Если он вспоминает неправильный контекст, он хуже, чем бесполезен — он опасен.
Почему пространства имён — это большое дело
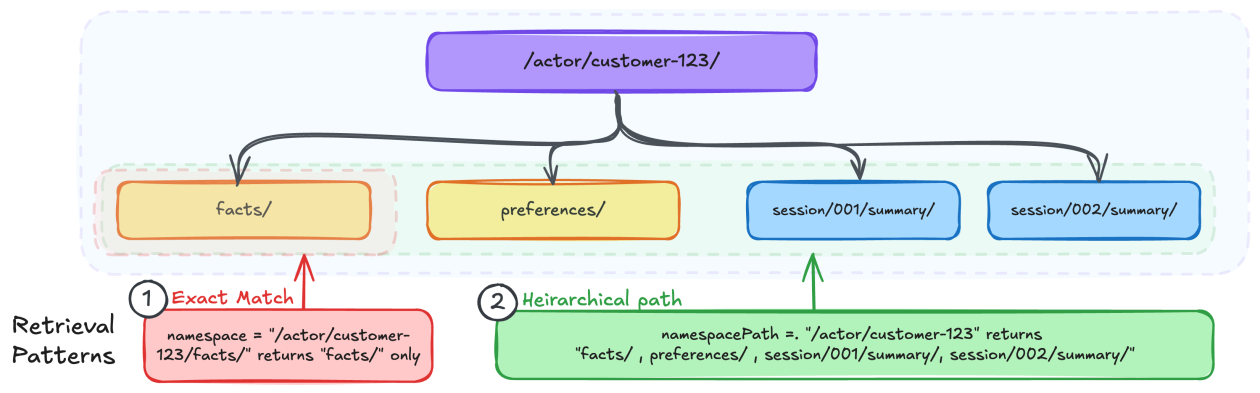
Так в чём же вся соль? Пространства имён (namespaces). По сути, это иерархические пути, как файловая система компьютера, которые определяют, где и как хранятся, и, что критически важно, извлекаются воспоминания. Аргумент Amazon заключается в том, что правильная структура — это основа построения эффективных систем памяти для этих агентов. И они не ошибаются.
Это не просто хранение данных; это контроль доступа и интеллектуальное извлечение. Кто имеет право видеть какие воспоминания? Когда они их видят? Ответы на эти вопросы встроены в дизайн пространств имён. Это разница между ИИ, который помнит ваши личные предпочтения, и тем, который случайно вываливает их незнакомцу. Уязвимости безопасности здесь — реальная проблема, и этот иерархический подход призван их смягчить.
Ключевые вопросы, которые Amazon заставляет вас задать ещё до написания кода, весьма показательны: кому нужен доступ? Какой уровень детализации требуется для извлечения? Каковы критические границы изоляции? Это не мелочи; это фундамент надёжного ИИ. Если вы когда-либо боролись с ключами партиций DynamoDB или структурами бакетов S3, ментальная модель должна показаться знакомой, но с важным отличием: пространства имён поддерживают иерархическое извлечение, а не только точные совпадения. Это меняет правила игры для гранулярного воспоминания.
Неужели это просто очередной корпоративный хайп?
Послушайте, «шаблоны проектирования пространств имён» звучат как нечто, порождённое в тускло освещённой серверной инженерами, которые питаются раменом и кофеином. Но реальность гораздо более приземлённая. Плохая организация памяти в ИИ означает неуместные ответы, дыры в безопасности и, в целом, неуклюжих цифровых помощников. Хорошая организация означает ИИ, который ощущается по-настоящему полезным, а не просто поисковой системой с манией величия.
Ядро этого нового дизайна составляют шаблоны пространств имён. Эти шаблоны используют переменные, такие как {actorId} (кто использует агента), {sessionId} (текущий разговор) и {memoryStrategyId} (какой тип памяти используется), для динамического создания этих организационных путей. Это сложно и, честно говоря, необходимо. Представьте агента, которому нужно запомнить ваши диетические ограничения для кулинарного приложения, детали рабочего проекта для инструмента продуктивности и предпочтительный музыкальный жанр для стримингового сервиса — и при этом держать всё это раздельно и безопасно. Вот где вступает в игру такая структурированная память.
Например, предпочтения пользователя могут храниться по пути /actor/customer-123/preferences/, а краткие сводки его сессий — по пути /actor/customer-123/session/session-789/summary/. Этот гранулярный контроль позволяет разработчикам указывать уровень извлечения точно там, где это необходимо, будь то краткая сводка одной сессии или накопленные за годы пользовательские предпочтения. Это уровень организации, который отличает полезный ИИ от цифрового шума.
Практические последствия для ИИ-агентов
Amazon описывает несколько паттернов для различных стратегий памяти. Для семантической памяти (изученные факты) и пользовательских предпочтений они выступают за актор-скопический подход. Это означает, что все факты и предпочтения для конкретного пользователя консолидируются под одним пространством имён, независимо от сессии, из которой они были получены. Это гарантирует, что знания, накопленные с течением времени, не будут потеряны или фрагментированы между различными разговорами. Это позволяет сформировать последовательное, развивающееся понимание пользователя.
И наоборот, для таких вещей, как сводки сессий, рекомендуется более сессионно-ориентированное пространство имён. Это предотвращает превращение ресурса памяти в монолитный ком всех разговоров. Ключ к успеху — адаптация пространства имён к типу памяти и его предполагаемому использованию. Речь идёт об эффективности и релевантности. Извлечение краткого содержания конкретной сессии не должно требовать просеивания многолетних общих предпочтений, и наоборот. Этот подход отражает то, как сама человеческая память категоризируется и к ней осуществляется доступ — не как единая, недифференцированная масса, а как структурированная сеть взаимосвязанной информации.
Это не просто академическое упражнение. Это создание ИИ, способного надёжно выполнять сложные задачи. Подумайте о боте поддержки клиентов, которому необходимо получить доступ ко всей истории пользователя — его прошлым покупкам, предыдущим обращениям в поддержку и даже заметкам из предыдущих взаимодействий — чтобы предоставить точную помощь. Без чётко определённой структуры памяти этот бот действовал бы вслепую, прося вас повторять информацию, которую вы уже давали дюжину раз.
Единственное уникальное наблюдение здесь? Такой уровень дизайна пространств имён — это тихое признание ограничений текущих архитектур LLM. Хотя LLM отлично генерируют текст, их способность поддерживать последовательную, долгосрочную, контекстуально релевантную память без явной архитектурной поддержки остаётся значительным препятствием. AgentCore Memory от Amazon с его сложными паттернами пространств имён, по сути, предоставляет необходимый каркас для преодоления этого присущего недостатка. Он создаёт прочную память вокруг эфемерной природы основной языковой модели.
«Правильный дизайн пространства имён имеет решающее значение для создания эффективной системы памяти».
Это не новая проблема в вычислениях, но её применение к динамичному, часто непредсказуемому миру ИИ-агентов представляет уникальные сложности. Описанные паттерны — актор-скопические, сессионно-скопические или даже более широкие группировки — это попытки внести порядок в потенциальный хаос постоянно развивающихся взаимодействий агентов. Это прагматичный шаг к тому, чтобы сделать ИИ-агентов более надёжными и менее склонными к тем же сбоям памяти, которые присущи менее сложным системам.
В конечном итоге, для обычного пользователя, взаимодействующего с ИИ, это означает более умных, более отзывчивых и более безопасных агентов. Это означает меньше разочаровывающих ситуаций, когда приходится повторять себя, и большее ощущение того, что ИИ действительно понимает и помнит. Речь идёт о переходе от ИИ, который просто осведомлен о текущем разговоре, к ИИ, который имеет подлинное, организованное и безопасное представление об истории.
🧬 Связанные материалы
- Читать далее: Скрытые ловушки памяти, убивающие ваш поиск Manticore — и панель мониторинга, которая их разоблачает
- Читать далее: Код ИИ для Node.js: Устаревший мусор, выдаваемый за прогресс
Часто задаваемые вопросы
Что на самом деле делает AgentCore Memory? AgentCore Memory — это функция в Amazon Bedrock, которая помогает ИИ-агентам хранить, организовывать и извлекать информацию из прошлых взаимодействий, позволяя им поддерживать контекст в разговорах. Она разработана, чтобы сделать агентов более полезными и персонализированными.
Повлияет ли новый дизайн пространств имён на мои текущие ИИ-агенты? Если вы используете или разрабатываете агентов с AgentCore Memory в Amazon Bedrock, вам потребуется учитывать эти новые шаблоны пространств имён при проектировании организации памяти для оптимальной производительности, извлечения данных и безопасности.
Чем это отличается от простого сохранения журнала разговоров? В отличие от простого журнала, пространства имён предоставляют структурированный способ категоризации и маркировки записей памяти, что позволяет осуществлять более интеллектуальное и целенаправленное извлечение. Речь идёт о семантической организации и контроле доступа, а не просто о хронологическом хранении.

