AIエージェントが情報を「保存」するだけだった時代は、もう古い。Amazonの最新の動き、すなわちAgentCore Memoryの刷新は、エージェントがその情報をいかに「見つけ出す」か、そして何より「安全に管理する」かに焦点を当てている。これは、単なる技術的な抽象論ではない。AIが意味のある学習と対話を行う上で、情報漏洩やデータのごった煮状態を防ぎ、実用的な能力を獲得するための、泥臭い現実との戦いなのだ。
要するに、AIエージェントの記憶の整理方法が根本から見直されている。これは、もはや忘れられた日記帳のようなものではなく、超整理されたファイルキャビネットのようなものだと考えてほしい。なぜこれが重要か? なぜなら、AIが適切な文脈を思い出せなければ、それは無用な存在だからだ。もし間違った文脈を思い出したら? それは無用どころか、危険ですらある。
名前空間が「ビッグディール」である理由
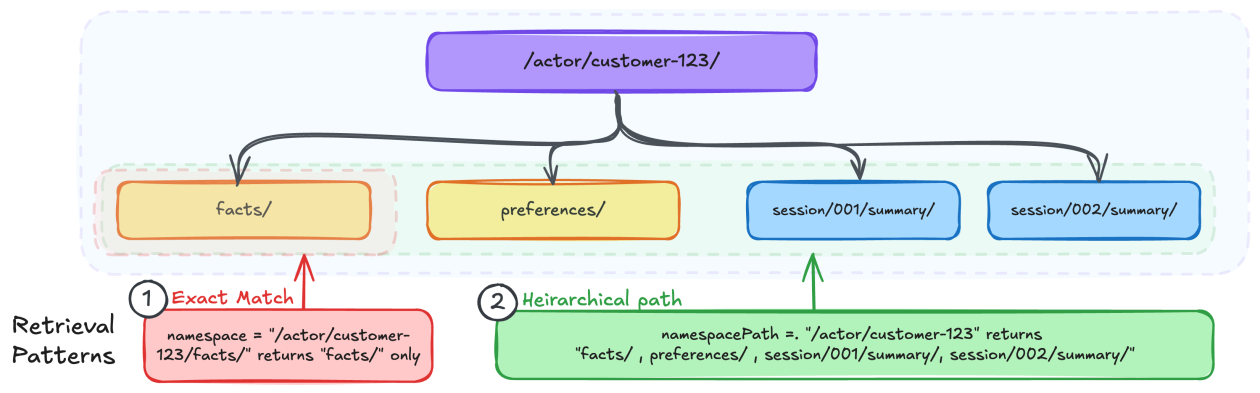
では、この名前空間(Namespaces)がなぜそれほど重要なのか? 名前空間とは、本質的には階層的なパスのようなものだ。コンピュータのファイルシステムを想像してもらえばいい。それが、記憶がどこに、どのように保存され、そして最も重要な、どうやって検索されるかを決定する。Amazonの主張は、この構造を正しく設計することが、エージェントのための効果的な記憶システム構築の基礎である、というものだ。そして、それは全くその通りだ。
これは単なるデータ保存の話ではない。アクセス制御とインテリジェントな検索の話だ。誰がどの記憶を見ることを許可されるのか? いつそれを見るのか? これらの問いへの答えは、名前空間の設計に埋め込まれている。これは、あなたの個人的な好みを覚えているAIと、それをうっかり見知らぬ人に漏らしてしまうAIとの違いだ。セキュリティ脆弱性は、ここで現実的な懸念事項であり、この階層的なアプローチはそれらを軽減することを目指している。
Amazonが、コードに触れる前に開発者に問いかける根源的な疑問は示唆に富む。「誰がアクセスを必要とするか?」「どのレベルの詳細度で取得する必要があるか?」「重要な分離境界は何か?」これらは些細なことではない。これらは信頼できるAIの礎なのだ。もしあなたがDynamoDBのパーティションキーやS3バケットの構造で苦労した経験があるなら、このメンタルモデルは馴染み深いだろう。しかし、決定的なひねりがある。名前空間は、単なる完全一致ではなく、階層的な検索をサポートする。それは、きめ細やかな記憶検索のためのゲームチェンジャーだ。
ただの企業の誇大広告か?
正直に言おう。「名前空間設計パターン」なんて言葉を聞くと、ラーメンとカフェインで生きているエンジニアたちが、薄暗いサーバー室で生み出したような響きがある。だが、現実はもっと地に足のついたものだ。AIにおける記憶の整理がまずければ、それは無関係な応答、セキュリティホール、そして全体的に頼りないデジタルアシスタントにつながる。良い整理は、偉ぶった検索エンジンではなく、真に役立つAIを生み出す。
この新しい設計の核心は、名前空間テンプレートにある。これらのテンプレートは、{actorId}(エージェントを使用しているユーザー)、{sessionId}(現在の会話)、{memoryStrategyId}(どのような種類の記憶か)といった変数を使用して、これらの整理パスを動的に作成する。これは洗練されており、率直に言って、必要不可欠だ。レシピアプリのためにあなたの食事制限を覚え、生産性ツールにあなたの仕事のプロジェクト詳細を覚え、ストリーミングサービスのためにあなたの好みの音楽ジャンルを覚える必要があるエージェントを想像してほしい。それらすべてを、明確かつ安全に区別しながら。そこで、この種の構造化された記憶が活躍するのだ。
例えば、ユーザーの好みは/actor/customer-123/preferences/の下に、セッションの要約は/actor/customer-123/session/session-789/summary/に配置されるかもしれない。このきめ細やかな制御により、開発者は、単一セッションの要約であれ、長年蓄積されたユーザーの好みであれ、正確に適切なレベルで検索を指定できる。これは、有用なAIとデジタルノイズを分ける組織化のレベルだ。
AIエージェントへの実践的な影響
Amazonは、さまざまな記憶戦略に対していくつかのパターンを提示している。意味記憶(学習した事実)やユーザーの好みについては、アクター(actor-scoped) スコープのアプローチを推奨している。これは、特定のユーザーに関するすべての事実と好みが、発生したセッションに関係なく、単一の名前空間の下に統合されることを意味する。これにより、時間とともに蓄積された知識が失われたり、ばらばらの会話に断片化されたりすることがなくなる。ユーザーの一貫した、進化する理解が可能になる。
逆に、セッションの要約のようなものについては、よりセッション固有の名前空間が推奨される。これにより、記憶リソースがあらゆる会話の単一の巨大な塊になるのを防ぐ。鍵は、名前空間を記憶の「種類」とその意図された用途に合わせることだ。効率と関連性の問題である。特定のセッションの要約を取得するために、長年の一般的な好みをすべてふるいにかける必要はないし、その逆もまた然りだ。このアプローチは、人間の記憶自体がどのように分類され、アクセスされるかを模倣している——単一の、区別されていない塊ではなく、相互接続された情報の構造化されたネットワークだ。
これは単なる学術的な演習ではない。信頼性の高い複雑なタスクを実行できるAIを構築するためのものだ。顧客サービスボットが、正確な支援を提供するために、ユーザーの完全な履歴――過去の購入履歴、以前のサポートチケット、さらには以前のやり取りからのメモ――にアクセスする必要がある状況を考えてほしい。明確に定義された記憶構造がなければ、そのボットは暗闇で手探り状態になり、あなたがすでに何度も伝えた情報を繰り返すように求めてくるだろう。
ここでのユニークな洞察は? このレベルの名前空間設計は、現在のLLMアーキテクチャの限界を静かに認めているということだ。LLMはテキスト生成に優れているが、明示的なアーキテクチャサポートなしに、一貫した長期的な、文脈に関連した記憶を維持する能力は、依然として大きなハードルだ。AmazonのAgentCore Memoryは、その洗練された名前空間パターンにより、この固有の弱点を克服するために必要な足場を提供している。それは、コア言語モデルの一時的な性質の「周り」に、耐久性のある記憶を構築しているのだ。
“名前空間設計を正しく行うことは、効果的な記憶システムを構築するために不可欠です。”
これはコンピューティングにおいては新しい問題ではないが、AIエージェントの動的で予測不可能な世界にそれを適用することは、独自の課題をもたらす。アクター・スコープ、セッション・スコープ、さらにはより広範なグループ化といった、説明されているパターンは、絶えず進化するエージェントのやり取りの潜在的なカオスに秩序をもたらそうとする試みだ。それは、AIエージェントをより信頼でき、洗練されていないシステムを悩ませる記憶の誤りから解放するための、実践的な一歩なのだ。
最終的に、AIと対話する平均的なユーザーにとって、これはより賢く、より応答性が高く、より安全なエージェントを意味する。それは、自分自身を繰り返すというフラストレーションの多い経験が減り、AIが実際に理解し、覚えているという感覚が高まることを意味する。それは、単に現在の会話を認識しているAIから、過去を真に、組織的に、そして安全に把握しているAIへの移行なのだ。
🧬 関連インサイト
よくある質問
AgentCore Memoryは具体的に何をするのですか? AgentCore Memoryは、Amazon Bedrock内の機能で、AIエージェントが過去のやり取りから情報を保存、整理、検索するのを助け、会話全体でコンテキストを維持できるようにします。エージェントをより役立ち、パーソナライズするために設計されています。
この新しい名前空間設計は、私の現在のAIエージェントに影響しますか? Amazon Bedrock AgentCore Memoryを使用している、または開発している場合、最適なパフォーマンス、検索、セキュリティのために、メモリ組織の設計においてこれらの新しい名前空間パターンを考慮する必要があります。
これは単なる会話ログの保存とどう違うのですか? 単純なログとは異なり、名前空間はメモリレコードを分類およびタグ付けするための構造化された方法を提供し、よりインテリジェントでターゲットを絞った検索を可能にします。これは、単なる時系列ストレージではなく、意味論的な組織化とアクセス制御の話です。

