Forget about AI agents just storing information. Amazon’s latest move with AgentCore Memory is about making sure they can actually find it, and importantly, keep it secure. This isn’t some abstract engineering problem; it’s the messy reality of building AI that can actually learn and interact meaningfully without becoming a leaky sieve or a data landfill.
Basically, they’re re-architecting how AI agents’ memories are organized. Think of it less like a forgotten diary and more like a hyper-organized filing cabinet. This matters because if an AI can’t recall the right context, it’s useless. If it recalls the wrong context, it’s worse than useless—it’s dangerous.
Why Namespaces are a Big Deal
So what’s the big deal? Namespaces. They’re essentially hierarchical paths, like a computer’s file system, that dictate where and how memories are stored and, crucially, retrieved. Amazon’s argument is that getting this structure right is fundamental to building effective memory systems for these agents. And they’re not wrong.
This isn’t just about storing data; it’s about access control and intelligent retrieval. Who gets to see what memory? When do they see it? The answers to these questions are embedded in the namespace design. It’s the difference between an AI that remembers your personal preferences and one that accidentally spills them to a stranger. Security vulnerabilities are a real concern here, and this hierarchical approach aims to mitigate them.
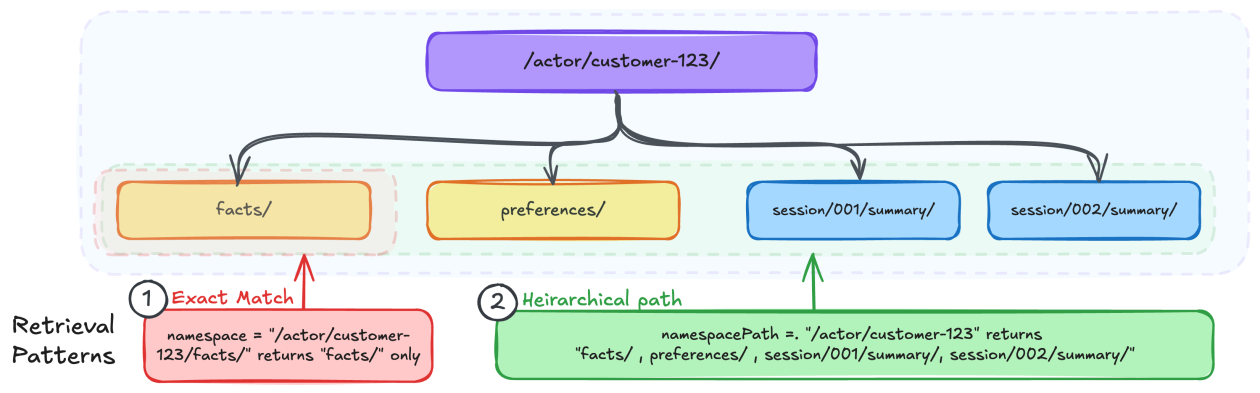
The core questions Amazon forces you to ask before even touching code are revealing: Who needs access? What level of detail do you need to retrieve? What are the critical isolation boundaries? These aren’t trivialities; they’re the bedrock of reliable AI. If you’ve ever wrestled with DynamoDB partition keys or S3 bucket structures, the mental model should feel familiar, but with a crucial twist: namespaces support hierarchical retrieval, not just exact matches. That’s a game-changer for granular recall.
Is This Just More Corporate Hype?
Look, “namespace design patterns” sounds like something conjured in a dimly lit server room by engineers who subsist on ramen and caffeine. But the reality is far more grounded. Bad memory organization in AI means irrelevant responses, security holes, and generally flailing digital assistants. Good organization means an AI that feels genuinely helpful, not just a glorified search engine with delusions of grandeur.
The core of this new design lies in namespace templates. These templates use variables like {actorId} (who is using the agent), {sessionId} (the current conversation), and {memoryStrategyId} (what kind of memory it is) to dynamically create these organizational paths. It’s sophisticated and, frankly, necessary. Imagine an agent that needs to remember your dietary restrictions for a recipe app, your work project details for a productivity tool, and your preferred music genre for a streaming service – all while keeping these distinct and secure. That’s where this kind of structured memory comes into play.
For example, a user’s preferences might live under /actor/customer-123/preferences/, while their session summaries are at /actor/customer-123/session/session-789/summary/. This granular control allows developers to specify retrieval at precisely the right level, whether it’s a single session’s summary or years of accumulated user preferences. It’s a level of organization that separates useful AI from digital noise.
Practical Implications for AI Agents
Amazon outlines several patterns for different memory strategies. For semantic memory (facts learned) and user preferences, they advocate for an actor-scoped approach. This means all facts and preferences for a specific user are consolidated under a single namespace, regardless of the session they originated from. This ensures that knowledge accumulated over time isn’t lost or fragmented across disparate conversations. It allows for a consistent, evolving understanding of the user.
Conversely, for things like session summaries, a more session-specific namespace is recommended. This prevents the memory resource from becoming a monolithic blob of every single conversation. The key is tailoring the namespace to the type of memory and its intended use. It’s about efficiency and relevance. Retrieving a specific session’s recap shouldn’t require sifting through years of general preferences, and vice-versa. This approach mirrors how human memory itself is categorized and accessed – not a single, undifferentiated mass, but a structured network of interconnected information.
This isn’t just an academic exercise. It’s about building AI that can reliably perform complex tasks. Think about a customer service bot that needs to access a user’s entire history – their past purchases, previous support tickets, and even notes from previous interactions – to provide accurate assistance. Without a well-defined memory structure, that bot would be fumbling in the dark, asking you to repeat information you’ve already given a dozen times.
One unique insight here? This level of namespace design is a quiet acknowledgment of the limitations of current LLM architectures. While LLMs are excellent at generating text, their ability to maintain consistent, long-term, contextually relevant memory without explicit architectural support is still a significant hurdle. Amazon’s AgentCore Memory, with its sophisticated namespace patterns, is essentially providing the necessary scaffolding to overcome that inherent weakness. It’s building a durable memory around the ephemeral nature of the core language model.
“Getting the namespace design right is essential to building an effective memory system.”
This isn’t a new problem in computing, but applying it to the dynamic, often unpredictable world of AI agents presents unique challenges. The patterns described—actor-scoped, session-scoped, or even broader groupings—are attempts to bring order to the potential chaos of constantly evolving agent interactions. It’s a pragmatic step towards making AI agents more dependable and less prone to the kind of memory lapses that plague less sophisticated systems.
Ultimately, for the average user interacting with AI, this means agents that are smarter, more responsive, and more secure. It means fewer frustrating experiences of repeating yourself and a greater sense of an AI that actually understands and remembers. It’s about moving from AI that’s merely aware of the current conversation to AI that has a genuine, organized, and secure grasp of history.
🧬 Related Insights
- Read more: The Hidden Memory Traps Killing Your Manticore Search — And the Dashboard That Exposes Them
- Read more: AI’s Node.js Code: Outdated Junk Posing as Progress
Frequently Asked Questions
What does AgentCore Memory actually do? AgentCore Memory is a feature within Amazon Bedrock that helps AI agents store, organize, and retrieve information from past interactions, enabling them to maintain context across conversations. It’s designed to make agents more helpful and personalized.
Will this new namespace design affect my current AI agents? If you are using or developing agents with Amazon Bedrock AgentCore Memory, the way you design your memory organization will need to consider these new namespace patterns for optimal performance, retrieval, and security.
How is this different from just saving a conversation log? Unlike a simple log, namespaces provide a structured way to categorize and tag memory records, allowing for more intelligent and targeted retrieval. It’s about semantic organization and access control, not just chronological storage.

