Запах озона и паленой пластмассы всё ещё висел в воздухе от стойки серверов, решившей самовоспламениться два дня назад.
Это мрачное напоминание, не так ли? Что в лабиринте сложных систем вас подводит не только откровенное злоупотребление. Часто это тонко ошибочный, кажущийся безобидным код, который не вписывается в более широкий операционный контекст. И вот тут, что тревожно, современные ИИ-ассистенты для написания кода начинают показывать свои слабые места.
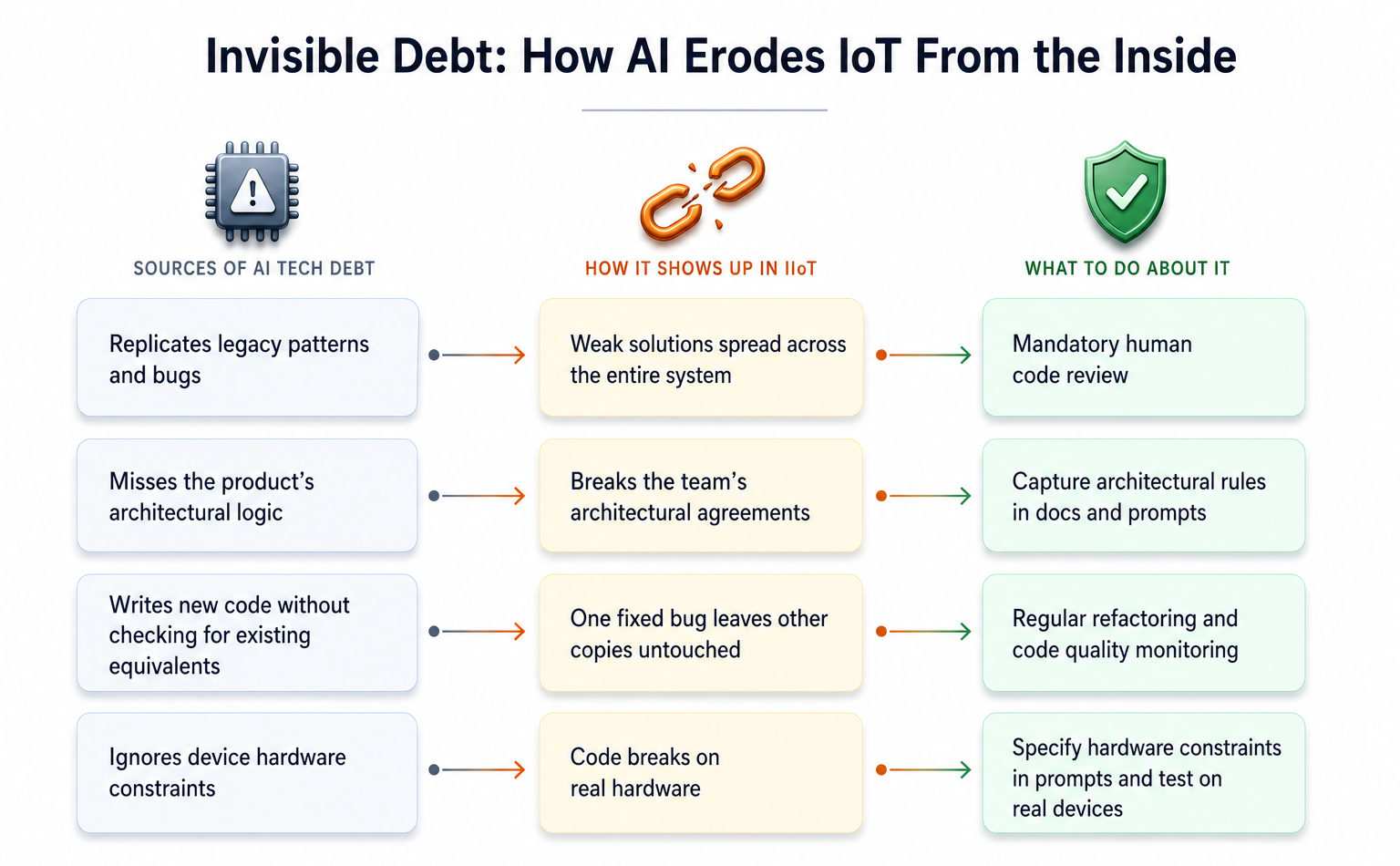
Будучи IIoT-специалистом, особенно глубоко погруженным в тонкости предиктивного обслуживания, я с пугающей регулярностью наблюдаю возникающий паттерн. ИИ-инструменты выдают работающий код, отмечая все локальные галочки, но при этом демонстративно упускают системную проверку здравого смысла. Они не проверяют собственные предположения на соответствие более масштабному проекту. В безжалостной среде промышленного Интернета вещей (IIoT) это означает, что фрагмент кода может быть идеален для своей непосредственной задачи — скажем, конкретной функции или микросервиса — но при этом совершенно не учитывать аппаратные ограничения, деликатный поток данных по сетям, незыблемые архитектурные границы или суровые реалии устройств, работающих «в поле». Последствия? Код, который локально безупречен, превращается в вектор системных сбоев, требующих дорогостоящих, трудоемких исправлений, тормозящих рост всей платформы.
Эхо-камера плохих привычек
ИИ-ассистенты работают, обучаясь на необъятном океане существующего кода. Проблема в том, что они не обладают врождённым архитектурным суждением. Они видят код, который вы им даёте, код вокруг, и выводят, как выглядит «хорошо». Если ваш проект уже обременён устаревшими подходами, неуклюжим дублированием данных или «хаками», маскирующимися под решения, ИИ не просто учится на этом — он принимает это как истину в последней инстанции. Он становится эхо-камерой, не только сохраняющей плохие практики, но и с пугающей скоростью их усиливающей. И это не теоретические страхи. Исследование, анализирующее более 300 000 коммитов, сгенерированных ИИ, в тысячах реальных репозиториев, показало, что более 15% этих коммитов содержали хотя бы один дефект качества кода, а четверть из них остались необработанными в финальном коде.
В системах Интернета вещей (IoT) этот унаследованный технический долг подобен лесному пожару. Шагкое решение, зашитое в прошивку, хлипкий сервисный шлюз или проницаемый обработчик телеметрии не остаётся изолированным. Оно распространяется с ужасающей эффективностью, становясь тихим заражением от устройства до самого облака.
Иллюзия «быстрых исправлений»
ИИ преуспевает в дискретных, чётко определённых задачах. Нужен юнит-тест? Шаблонный код? Стандартная CRUD-точка входа? ИИ может выдать это за считанные минуты. Но ему не хватает целостного видения. Он не знает, какие базы данных что хранят, каковы допустимые пределы пропускной способности или как разные компоненты должны взаимодействовать друг с другом. Анализ Ox Security более чем 300 open-source проектов, значительная часть которых была разработана с помощью ИИ, выявил функциональный код, да, но явно лишенный архитектурного предвидения. ИИ, оптимизируя для текущего промпта и не имея явных архитектурных ограждений — будь то в документации, проектных записях или самом промпте — с радостью создаст код, который тонко саботирует установленную топологию системы.
Представьте IIoT-систему, где временные ряды, справочные данные и логи добросовестно хранятся в отдельных, специализированных базах данных. ИИ, получив запрос на сохранение новых данных, может быть в блаженном неведении об этой установленной архитектуре, генерируя код, который незаметно нарушает эти критические соглашения, вынуждая в дальнейшем усложнять извлечение данных.
Скрытая стоимость дублирования логики
И, наконец, само по себе разрастание дублированной логики. ИИ-ассистент, по своей природе, не знает, что именно та же самая функциональность, которая вам нужна — скажем, для парсинга конкретного пакета данных или проверки сетевого соединения — уже существует где-то ещё в вашей разросшейся кодовой базе. Поэтому он пишет её снова. Результат — гидра идентичной логики, разбросанной по всей системе. Когда, в конечном итоге, потребуется внести изменения — исправить ошибку, оптимизировать производительность — разработчикам предстоит настоящая охота за сокровищами, попытка найти каждый отдельный экземпляр этого дублированного кода. Анализ GitClear миллионов строк кода за период с 2020 по 2024 год показал тревожную тенденцию: дублирование кода выросло с 8,3% до 12,3%, причем 2024 год стал первым годом, когда дублирование опередило рефакторинг. ИИ-инструменты готовы экспоненциально ускорить этот процесс. Они предлагают соблазнительную лёгкость вставки нового кода одной командой, но редко побуждают разработчика задуматься, существует ли уже похожий код.
В IoT это сценарий ночного кошмара. Если одна и та же логика парсинга пакетов независимо реализована в прошивке, в шлюзе и в облачном сервисе, исправление ошибки в одном экземпляре без нахождения других приведёт к тому, что устройства начнут вести себя непоследовательно. Синхронизация обновлений прошивки на тысячах или даже миллионах устройств в поле для исправления таких тонких несоответствий — монументальная, часто непреодолимая задача.
Укрощение ИИ-зверя: прагматичный подход
Так в чём же выход? Полностью отказаться от ИИ-инструментов? Это кажется столь же маловероятным, как и отмена изобретения книгопечатания. Настоящее поле битвы, как всегда, лежит в области управления и разумной интеграции. Речь идёт о создании надёжных ограждений. Это означает чрезвычайную детализацию наших промптов, точное определение архитектурных ограничений и желаемых результатов. Это означает строгие ревью кода, направленные не только на функциональную корректность, но и на соответствие архитектуре. Мы должны относиться к коду, сгенерированному ИИ, как к предложениям, требующим валидации, а не как к безошибочным командам.
Представьте себе так: если бы младший инженер написал код, который привел к архитектурному дрейфу, вы бы заметили это на ревью кода. Мы должны применить такую же тщательность, такое же архитектурное радарное наблюдение, к вкладу, генерируемому ИИ. Будущее надёжных, поддерживаемых систем — особенно в требовательных областях, таких как IoT — зависит от нашей способности направлять эти мощные инструменты, а не просто следовать за ними.
Будущее ИИ и технического долга
Это не просто техническая проблема; это экономическая. Стоимость рефакторинга технического долга, внесённого ИИ, может легко затмить любые первоначальные выгоды от скорости разработки. Компании, которые не смогут внедрить надёжные конвейеры валидации для кода, генерируемого ИИ, обнаружат себя в вечной погоне за ошибками и архитектурными несоответствиями, что в конечном итоге замедлит инновации и подорвёт доверие клиентов. Обещание ИИ — это скорость и эффективность; опасность заключается в его способности маскировать распад до тех пор, пока не станет слишком поздно для спасения.
🧬 Связанные материалы
- Читайте также: Claude Code’s Cron Heartbeat: OpenClaw’s Ghost Without the Daemon Bloat
- Читайте также: Claude Code 101: Tokens Tax Your Wallet, Context Windows Lie
Часто задаваемые вопросы
Что означает технический долг в контексте ИИ для разработчиков? Это означает, что код, сгенерированный ИИ, хотя и кажется функциональным, может содержать тонкие архитектурные недостатки или логические дубликаты, исправление которых потребует значительного времени и усилий в будущем, замедляя дальнейшую разработку.
Могут ли ИИ-инструменты действительно заменить разработчиков? Хотя ИИ-инструменты могут автоматизировать многие задачи кодирования, им в настоящее время не хватает критического архитектурного суждения, контекстуального понимания и творческого подхода к решению проблем опытных человеческих разработчиков. Их лучше рассматривать как мощных ассистентов, а не замену.
Как компании могут предотвратить создание технического долга ИИ? Компании должны внедрять строгие политики управления, детальный инжиниринг промптов, тщательные процессы ревью кода с акцентом на соблюдение архитектуры, а также непрерывный мониторинг качества кода и согласованности системы.

