2日前に自焼したサーバーラックからは、まだオゾンと焼けたプラスチックの匂いが漂っていた。
これは、身にしみる教訓ではないか? 複雑なシステムの迷宮では、致命傷となるのは、しばしば露骨な不正行為ではなく、より広範な運用コンテキストにマッピングされない、微妙に間違った、一見無害なコードなのだ。そして、驚くべきことに、現代のAIコーディングアシスタントがまさにほころびを見せ始めているのがこの点だ。
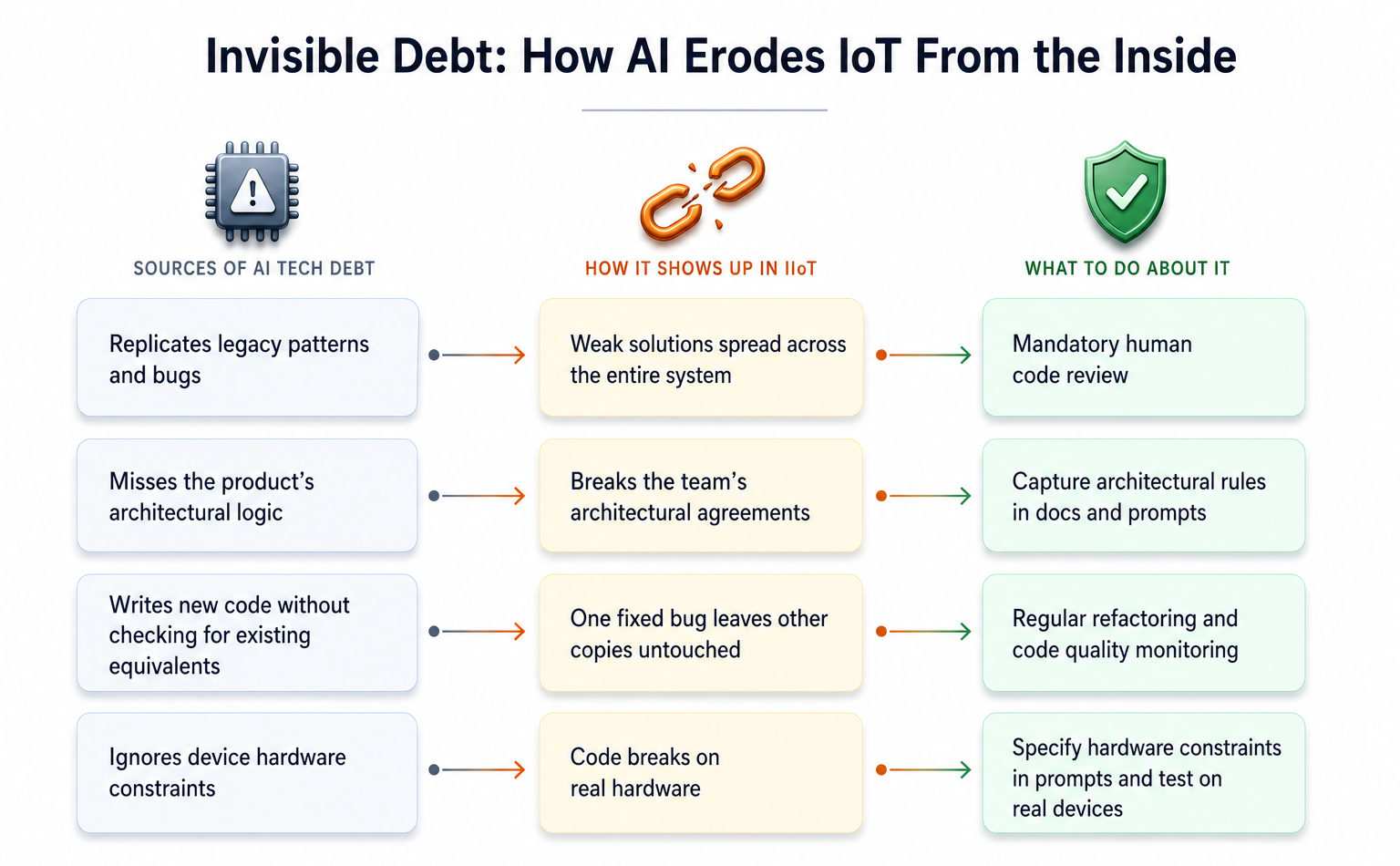
IIoT(産業用IoT)の専門家として、特に予知保全の最前線にいる私が見ているのは、冷ややかなまでの頻度で現れるパターンだ。AIツールは機能するコードを素早く生成し、局所的な要件はすべて満たす。しかし、システム全体の整合性チェックからは、あからさまに欠落している。それらは自身の仮定を、より大きな設計に対して検証しない。工業用IoTの容赦ない環境では、これは、特定の関数やマイクロサービスといった、その即時のタスクには完璧なコードが、ハードウェアの制約、ネットワークを横断するデータの繊細な流れ、不可侵なアーキテクチャ境界、あるいは現場で稼働するデバイスの過酷な現実に対して、完全に盲目であることを意味する。その結果は? 局所的には正しく見えるコードが、システム全体にわたる障害のベクトルとなり、プラットフォーム全体の成長を阻害する、高価で時間のかかる修正を要求するのだ。
悪しき習慣の残響室
AIアシスタントは、既存のコードの広大な海から学習することによって機能する。問題は、それらが本来、アーキテクチャ判断力を持っていないことだ。それらは、与えられたコード、周囲のコードを見て、「良い」ものがどのように見えるかを推論する。もしあなたのプロジェクトがすでに時代遅れのアプローチ、扱いにくいデータ重複、あるいは「ハック」まがいの解決策で満載されているなら、AIはそこから学ぶだけでなく、それを絶対的な真理として採用する。それは残響室となり、不良なプラクティスを保存するだけでなく、驚くべき速さでそれらを増幅する。これも理論上の心配事ではない。数千の実際のレポジトリにわたる30万件以上のAI生成コミットを分析した研究では、これらのコミットの15%以上が少なくとも1つのコード品質問題を抱えており、そのうちの4分の1は最終コードで未修正のままだったことが判明した。
IoTシステムでは、この継承された技術的負債は、野火のようなものだ。ファームウェアに組み込まれた不安定なソリューション、脆いゲートウェイサービス、あるいは浸透しやすいテレメトリプロセッサは、孤立したままではいない。それは、デバイスからクラウドまで、静かな感染源として、恐ろしい効率で伝播していく。
「クイックフィックス」という幻想
AIは、個別の、明確に定義されたタスクに長けている。単体テストが必要か? ボイラープレートコードか? 標準的なCRUDエンドポイントか? AIはそれらを瞬時に生成できる。しかし、全体像を把握する能力は欠けている。どのデータベースがどのデータを保持しているか、許容されるスループットの上限は何か、あるいは異なるコンポーネントがどのように連携するはずなのか、それらを知らない。Ox SecurityがAI支援を受けたプロジェクトを含む300以上のオープンソースプロジェクトを分析した結果、機能的なコードはあったものの、アーキテクチャの先見性に欠けていたことが明らかになった。AIは、即時のプロンプトを最適化し、ドキュメント、設計記録、あるいはプロンプト自体における明示的なアーキテクチャ上のガードレールを欠いているため、確立されたシステムトポロジを微妙に破壊するコードを喜んで作成する。
時系列データ、参照データ、ログが、それぞれ専用に設計された別々のデータベースに注意深く格納されているIIoTシステムを想像してほしい。新しいデータを格納するように指示されたAIは、この確立されたアーキテクチャに気づかず、これらの重要な合意を静かに侵害するコードを生成し、後々、複雑なデータ取得を強いる可能性がある。
ロジック重複の隠れたコスト
そして、ロジックの純粋な増殖もある。AIアシスタントは、その性質上、あなたがまさに必要としている機能(特定のデータパケットの解析やネットワーク接続の検証など)が、あなたの広大なコードベースのどこかにすでに存在することを知らない。そのため、それを再度記述してしまう。結果として、同一のロジックのヒドラが、システム全体に散らばる。変更が必要になったとき——バグ修正、パフォーマンス調整——開発者は、その重複コードのすべてのインスタンスを見つけようと、宝探しに駆り出されることになる。GitClearの2020年から2024年までの数百万行のコード分析は、憂慮すべき傾向を示した。重複コードの割合は8.3%から12.3%に増加し、2024年は重複がリファクタリングを上回った最初の年となった。AIツールは、この傾向を指数関数的に加速させる可能性を秘めている。それらは、単一のコマンドで新しいコードを挿入するという魅力的な容易さを提供するが、開発者に類似のコードがすでに存在するかどうかを検討するように促すことはめったにない。
IoTでは、これは悪夢のようなシナリオだ。同じパケット解析ロジックが、ファームウェア、ゲートウェイ、クラウドサービスで個別に実装されている場合、他のインスタンスを見つけずに1つのインスタンスのバグを修正すると、デバイスの動作に一貫性がなくなる。このような微妙な不整合を修正するために、数千、あるいは数百万ものデバイスのファームウェアアップデートを同期することは、途方もなく、しばしば達成不可能なタスクだ。
AIという獣を飼いならす:実践的なアプローチ
では、答えは何だろうか? AIツールを完全に放棄することか? それは、印刷機の発明を無かったことにするのと同じくらいありそうにない。いつものように、真の戦場はガバナンスとインテリジェントな統合にある。それは、強力なガードレールを構築することだ。これは、プロンプトにおいて極めて明示的であり、アーキテクチャ上の制約と望ましい結果を外科的な精度で定義することを意味する。これは、機能的な正しさだけでなく、アーキテクチャ上の整合性についても、厳格なコードレビューを意味する。AI生成コードは、不朽のコマンドではなく、検証を必要とする提案として扱う必要がある。
このように考えてほしい。もしジュニアエンジニアがアーキテクチャのドリフトを導入するコードを書いたとしたら、コードレビューで見つけるだろう。私たちは、AI生成の貢献に対しても、同じような精査、同じようなアーキテクチャレーダーを適用する必要がある。強力で保守可能なシステム、特にIoTのような要求の厳しい分野におけるシステムの将来は、これらの強力なツールに単に導かれるのではなく、それらを導く能力にかかっている。
AIと技術的負債の未来
これは単なる技術的な問題ではなく、経済的な問題でもある。AIが導入した技術的負債をリファクタリングするコストは、初期の開発速度の向上分を容易に上回る。AI生成コードの強力な検証パイプラインを確立できなかった企業は、バグやアーキテクチャの不整合を永遠に追いかけることになり、最終的にはイノベーションを遅らせ、顧客の信頼を損なうことになる。AIの約束はスピードと効率だが、その危険性は、手遅れになるまで腐敗を隠蔽する能力にある。
🧬 関連インサイト
よくある質問
AIにおける技術的負債は開発者にとって何を意味しますか? AIによって生成されたコードは、機能しているように見えても、微妙なアーキテクチャ上の欠陥や論理的な重複を導入する可能性があり、後で修正するためにかなりの時間と労力を要し、将来の開発を遅らせることを意味します。
AIツールは実際に人間の開発者を置き換えることができますか? AIツールは多くのコーディングタスクを自動化できますが、現在、経験豊富な人間の開発者が持つ重要なアーキテクチャ判断、文脈理解、問題解決の創造性を欠いています。それらは、置き換えではなく、強力なアシスタントとして見なされるのが最善です。
企業はAIが技術的負債を生み出すのをどのように防ぐことができますか? 企業は、厳格なガバナンスポリシー、詳細なプロンプトエンジニアリング、アーキテクチャ遵守に焦点を当てた厳格なコードレビュープロセス、およびコード品質とシステムの一貫性の継続的な監視を実装する必要があります。

