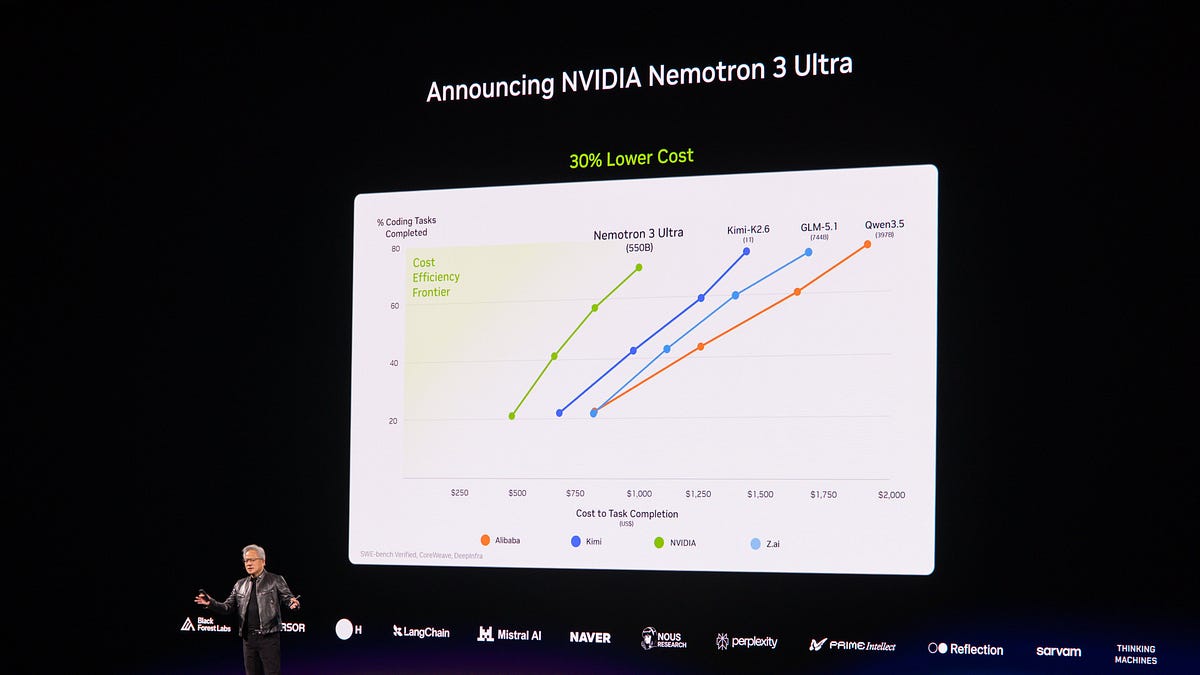
The news, for many developers and aspiring data scientists, isn’t just a list of interview questions. It’s a chance to solidify understanding of a cornerstone machine learning algorithm: the Support Vector Machine. This isn’t about cramming for a test; it’s about building the intuition needed to actually build intelligent systems, to debug them, and to explain why they work (or don’t work) in the messy reality of data.
Beyond Linear Boundaries
Why do linear classifiers throw their hands up when faced with datasets that aren’t neatly separable? It’s elementary, really. Imagine trying to draw a single straight line to divide points scattered in a circle. You can’t. Linear models, by definition, operate in a linear subspace. If your data points – the very representations of your problem – exist in a way that requires a curve, a bend, or a complex boundary to separate classes, a simple line will inevitably misclassify a significant chunk.
And how do we escape this straight-jacket? Feature transformation techniques are the heroes here. Think of it as giving your data a new perspective. By applying functions to your original features, you can project them into a higher-dimensional space where a linear separation might become possible. It’s a bit like taking a 2D projection of a 3D object and realizing you can’t see its true form until you rotate it. The trick is finding the right projection – the right transformation.
The Magic of the Kernel Trick
This brings us to the heart of SVM’s power: the kernel trick. What is it, really? It’s a clever mathematical shortcut. Instead of explicitly transforming your data into that high-dimensional space (which can be computationally expensive, sometimes infinitely so), kernel functions allow us to compute the dot products between pairs of data points as if they were in that higher space, without ever having to explicitly calculate their coordinates there. It’s a ghost in the machine, a phantom transformation that delivers the result.
“The kernel trick is a way to compute a dot product between two feature vectors in a high-dimensional space without ever actually computing the coordinates of the data in that space.”
This computational elegance is why kernel functions are considered so potent. They grant SVM the ability to model complex, non-linear relationships with relative ease. From the simple linear kernel to the more nuanced polynomial and Radial Basis Function (RBF) kernels, each offers a different way to shape the decision boundary, allowing SVMs to adapt to a wide range of data structures. RBF, in particular, with its Gaussian distribution, can create arbitrarily complex boundaries – a powerful tool for thorny classification problems.
The Downsides and the Nuances
But nothing’s a silver bullet. Kernel methods, while powerful, come with their own set of challenges. For one, choosing the right kernel and its associated hyperparameters (like gamma for RBF or degree for polynomial) can feel like an art form, often requiring significant experimentation and validation. Overfitting is also a real concern; a highly complex kernel can memorize the training data, leading to poor performance on unseen data. Furthermore, the interpretability of the model can suffer. When you’re operating in an abstract, high-dimensional space, explaining why a specific prediction was made becomes significantly harder than with a simple linear model.
So, is SVM inherently linear or non-linear? It’s both, and neither. At its core, SVM is a linear classifier that finds an optimal hyperplane. However, through the ingenious application of kernel functions, it can behave as a non-linear classifier. The algorithm itself operates linearly on transformed feature spaces, but the outcome can be highly non-linear with respect to the original data.
Extending the Reach
Handling multi-class classification tasks with SVMs isn’t as straightforward as binary classification. The common approaches involve strategies like ‘one-vs-rest’ (training a binary classifier for each class against all others) or ‘one-vs-one’ (training a binary classifier for every pair of classes). Each has its trade-offs in terms of computational cost and performance. And yes, kernels aren’t exclusive to SVMs; they pop up in other algorithms too, a proof to their utility in tackling high-dimensional data.
Under what circumstances does SVM shine brighter than, say, Logistic Regression? When the data exhibits complex, non-linear decision boundaries, SVM with an appropriate kernel is often superior. Logistic Regression, being fundamentally a linear model (unless you manually engineer non-linear features), will struggle to capture complex patterns. SVM’s ability to implicitly map data into higher dimensions gives it an edge in such scenarios, particularly when the margin of separation between classes is critical.
The author’s lighthearted approach, complete with doodles, belies a serious examination of a fundamental ML concept. It’s a welcome contrast to the dry, often impenetrable corporate pronouncements that often surround AI development. This isn’t just about passing an interview; it’s about understanding the plumbing of modern AI.