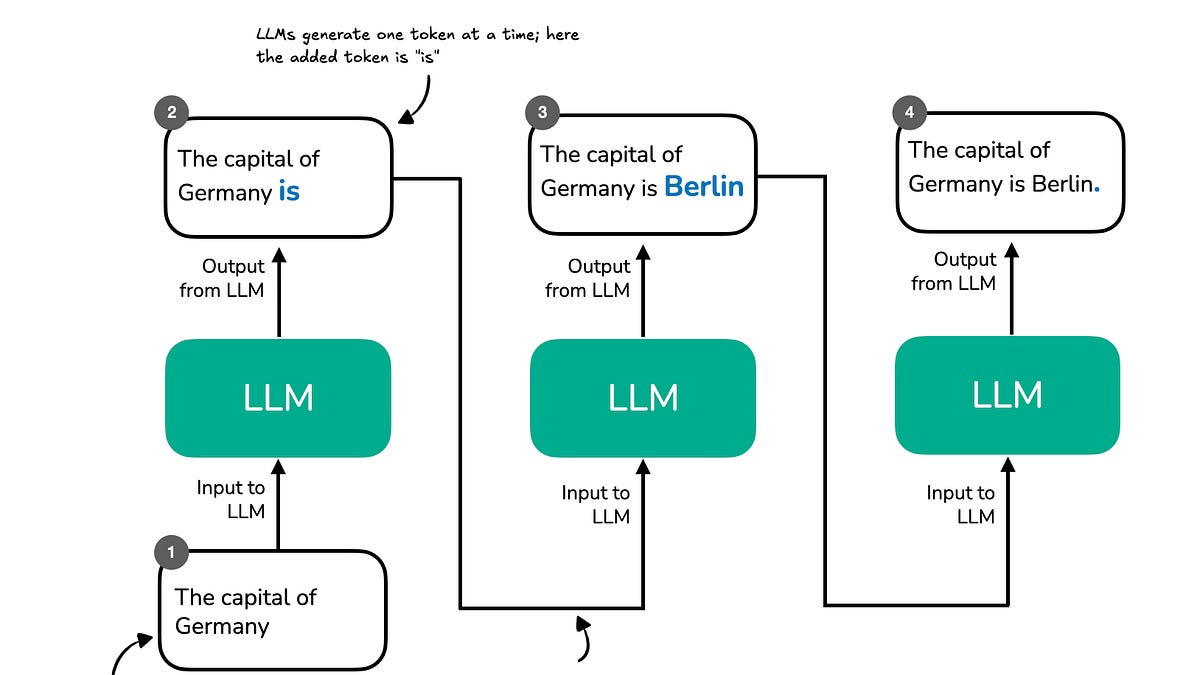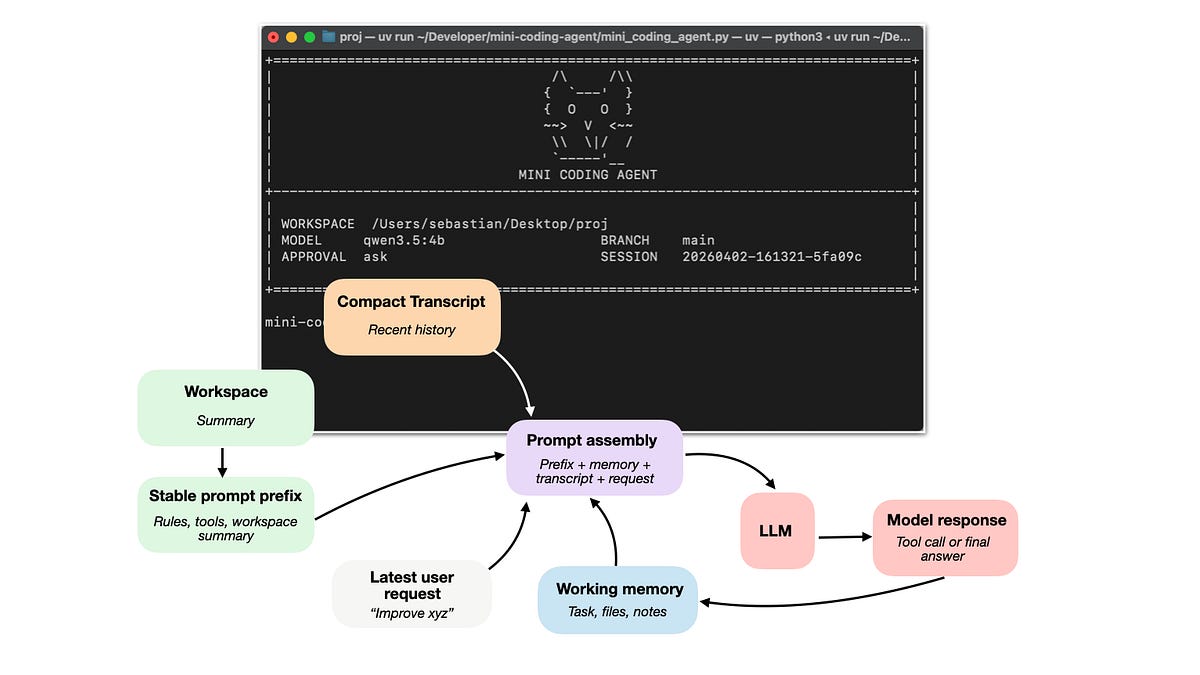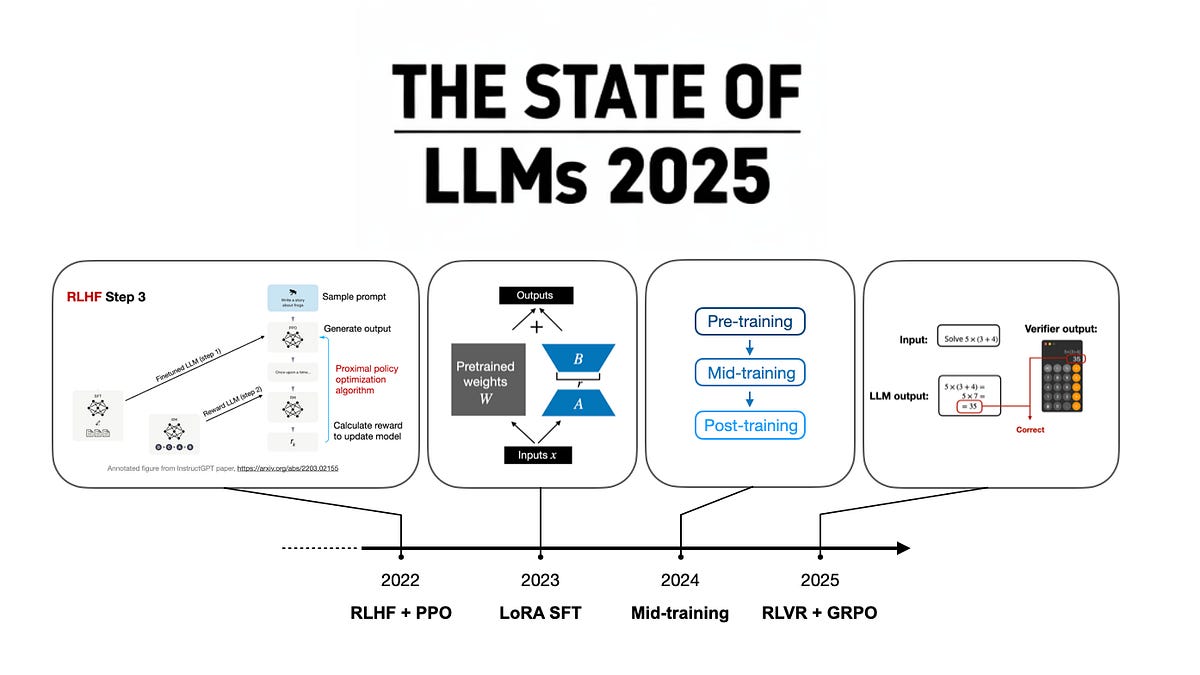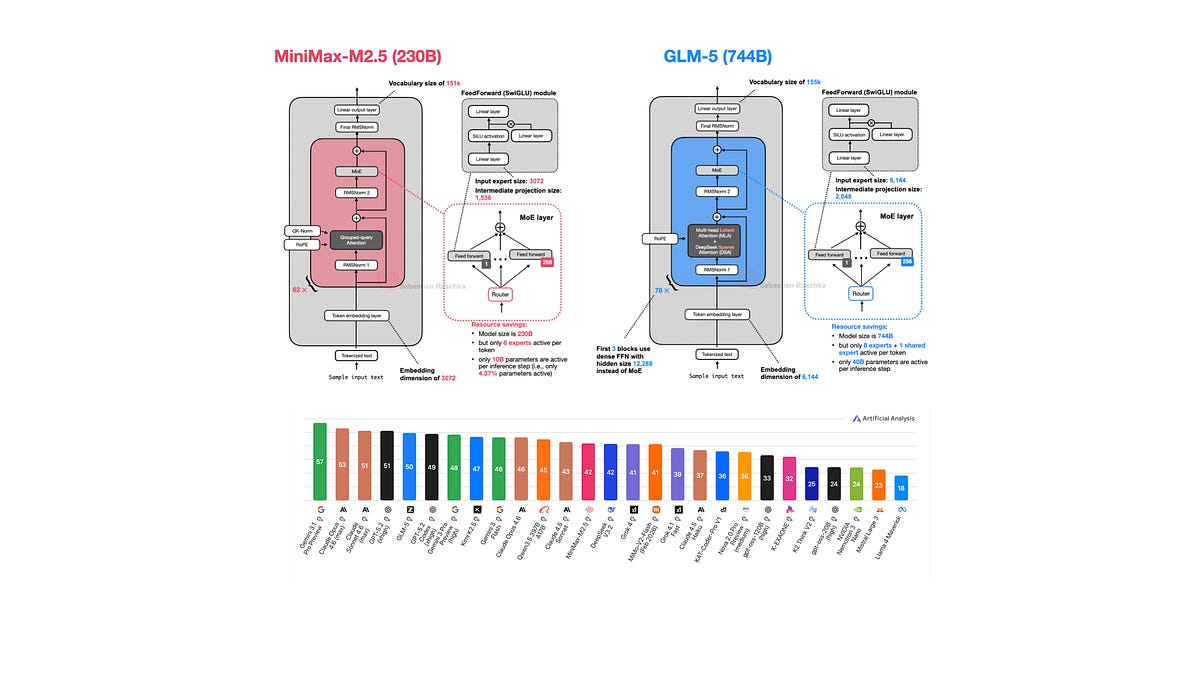
Large Language Models
gpt-oss Unpacked: From GPT-2's Roots to Qwen3 Rivalry
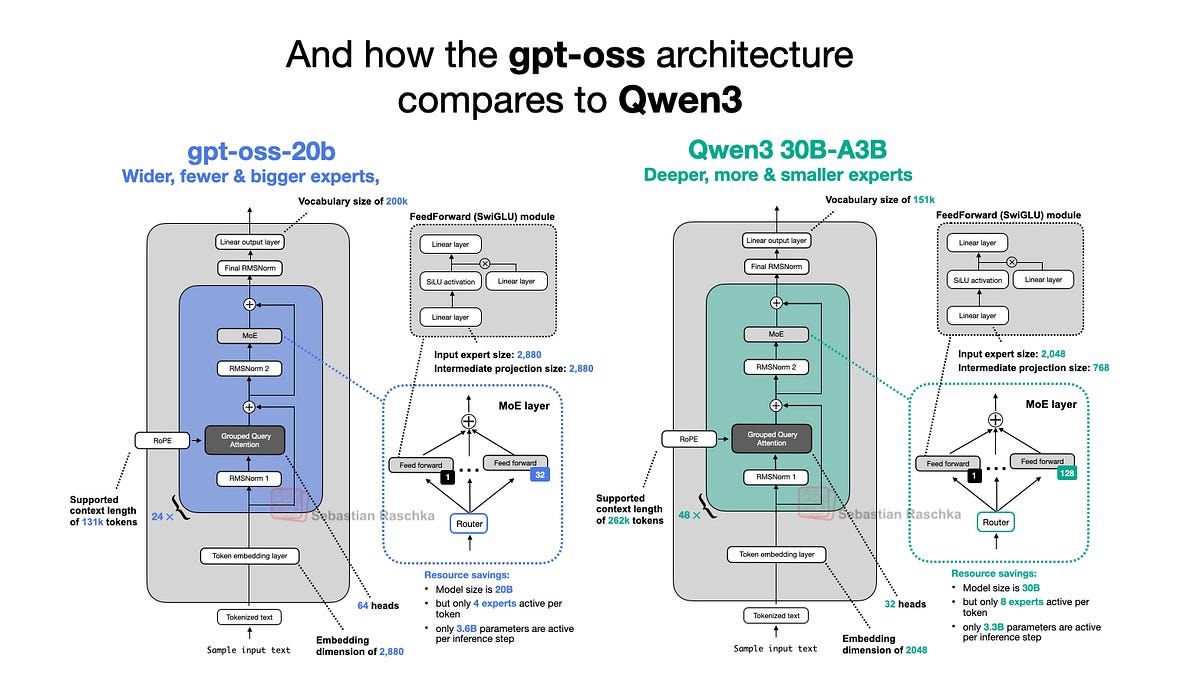
OpenAI just cracked open gpt-oss-120b and 20b, echoing GPT-2's 2019 shock. But smarter architectures and GPU tricks make them runnable at home—here's the deep architecture breakdown.