Is your understanding of linear regression purely a statistical pursuit, or are you tapping into its predictive power like a machine learning practitioner? This isn’t just an academic quibble; it’s a fundamental split in how we wield one of data science’s most enduring tools.
Look, the math underpinning linear regression is the same—at its core, it’s about finding the best-fitting line through data points by minimizing the sum of squared errors. The coefficients, the intercepts, the R-squared values: these are common currency. But the why and the how diverge dramatically.
The Statistical Lens: Inference First
For statisticians, linear regression is primarily an inferential tool. The goal isn’t just to predict, but to understand relationships. They want to know if a variable has a statistically significant impact on another, and crucially, the direction and magnitude of that impact. This means a heavy emphasis on hypothesis testing, confidence intervals for coefficients, and diagnostics to ensure the underlying assumptions of the model (like homoscedasticity and normality of residuals) hold true. It’s about explaining variance and drawing conclusions about a population based on a sample.
Here’s a quote that captures this essence:
In statistical modeling, the focus is often on interpretability and understanding the causal relationships between variables, rather than solely optimizing predictive accuracy.
This mindset drives the rigorous scrutiny of model assumptions. A statistically significant result is prized, but not at the expense of understanding the uncertainty around that finding.
The Machine Learning Angle: Prediction Dominates
The machine learning practitioner, on the other hand, views linear regression through the lens of prediction. The emphasis shifts from explaining relationships to forecasting outcomes. While interpretability is valued, it often takes a backseat to predictive performance. Does the model accurately predict new, unseen data? Are the coefficients producing the best possible forecast, even if their individual statistical significance is questionable?
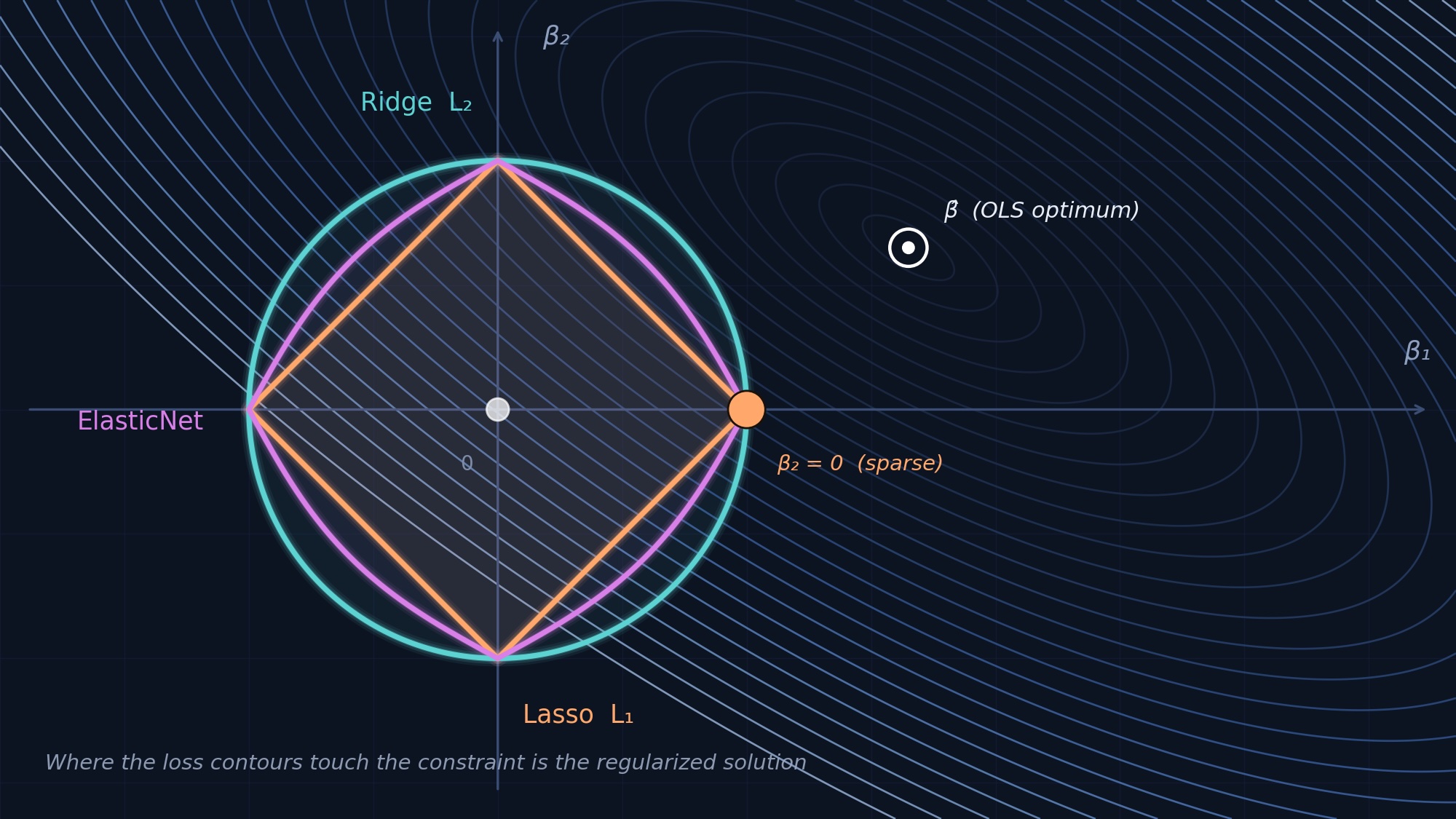
Here, techniques like regularization (Lasso, Ridge) become paramount. These methods, which penalize large coefficients, are designed to prevent overfitting and improve generalization to new data. They might shrink coefficients to near zero, making them statistically “less significant” in the traditional sense, but dramatically boosting predictive accuracy. Cross-validation becomes the arbiter of success, not p-values.
Where the Divergence Matters
This isn’t a purely theoretical distinction. Consider a scenario where a marketing team wants to understand how ad spend affects sales. A statistician will build a model, test the significance of ad spend’s coefficient, and report the confidence interval—essentially saying, ‘We’re X% confident that a dollar increase in ad spend leads to a $Y to $Z increase in sales.’ This informs strategic decisions about budget allocation.
A machine learning engineer, faced with the same problem, might build a similar model but then apply regularization. They might find that while ad spend is statistically significant, its coefficient is slightly volatile. By regularizing, they might achieve a more stable and accurate prediction of future sales based on ad spend, even if the exact statistical “significance” of the ad spend coefficient is less clear-cut. The focus is on saying, ‘Given this ad spend, we predict sales will be approximately $W.’
The Data-Driven Analyst’s Take
The market for data science tools and platforms reflects this dichotomy. You have tools geared towards statistical inference and reporting, and then you have platforms optimized for large-scale model training, hyperparameter tuning, and deployment for prediction. Both are valid applications of linear regression.
But here’s the thing: in the current AI gold rush, the machine learning perspective often gets amplified. The buzz around predictive accuracy, deep learning architectures, and generative AI can overshadow the enduring power and necessity of statistical inference. Companies pouring billions into AI are often building systems that, at their core, use predictive models derived from principles like linear regression. Yet, the PR often focuses on the ‘intelligence’ rather than the statistically sound (or sometimes, statistically questionable) forecasting.
My unique insight? The conflation of statistical inference with machine learning prediction creates a blind spot. We risk devaluing the crucial role of understanding causality and uncertainty, which are foundational to strong, ethical AI development. Just because a model predicts well doesn’t mean it understands well, or that its predictions are truly attributable to the factors we think are driving them.
Is Linear Regression Still Relevant?
Absolutely. It’s the foundational building block for countless more complex models. Understanding its dual nature—as both an inferential and predictive tool—is key to leveraging it effectively. The skill isn’t just in fitting a line; it’s in knowing why you’re fitting it and what you intend to do with the results.
🧬 Related Insights
- Read more: Microsoft IPs Scan 287 Sneaky Web Shells: Attackers’ Hit List Exposed
- Read more: Cursor’s Crown Slips: 8 Alternatives Developers Are Flocking To Now
Frequently Asked Questions
What is the main difference between statistical and machine learning linear regression? Statistical regression focuses on inference and understanding relationships, emphasizing hypothesis testing and model assumptions. Machine learning regression prioritizes predictive accuracy on new data, often using regularization and cross-validation.
Will linear regression be replaced by more advanced AI? Linear regression is a foundational algorithm. While more complex AI models exist for specific tasks, the principles of linear regression are embedded in many of them and it remains a vital tool for simpler predictive and explanatory tasks.
Can I use statistical regression for prediction? Yes, statistical regression models can certainly be used for prediction. However, machine learning approaches often optimize more aggressively for predictive performance, sometimes at the expense of traditional statistical interpretability.