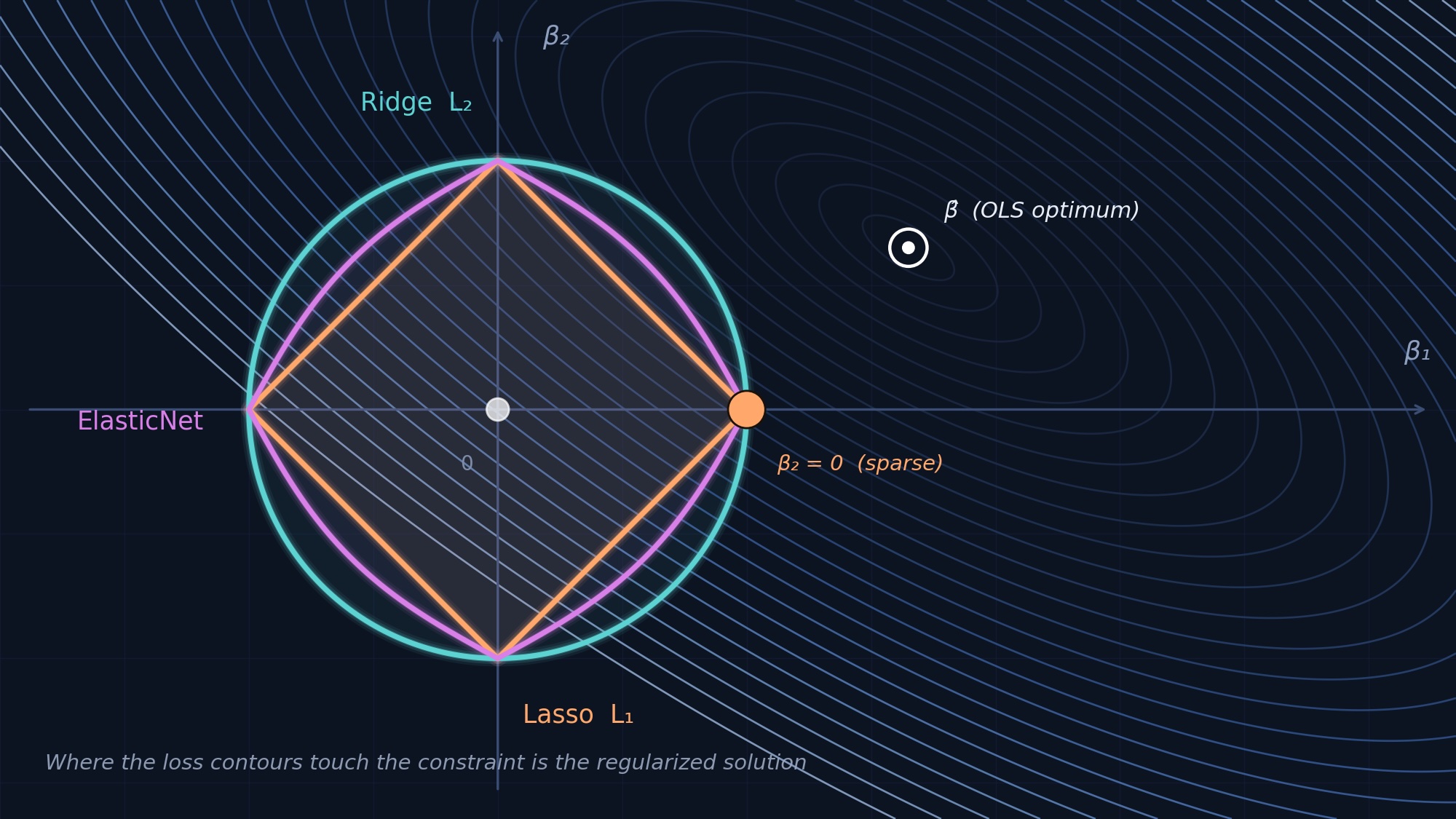
Look, we’ve all been there. Staring at scikit-learn’s menu: RidgeCV, LassoCV, ElasticNetCV. Do you pick what the blog post said? What your coworker swore by? Or do you just throw them all at the wall and hope something sticks?
Well, a couple of folks at Instacart decided to stop the guesswork. They crunched through 134,400 simulations — yes, you read that right — to see if they could actually tell us which regularizer to use. And the results? They’re… interesting. And frankly, a little anticlimactic for those who like a good tech showdown.
Prediction vs. Reality: Who Cares About Accuracy?
Forget the endless debates. For the vast majority of us just trying to get a model to predict stuff, the headline is this: it barely matters. Ridge, Lasso, and ElasticNet are practically interchangeable for predictive accuracy. We’re talking differences in median RMSE of less than 0.3%. Unless you’ve got a ridiculously small dataset (fewer than 78 observations per feature, which is practically microscopic in production), the nuances between these regularization techniques get drowned out.
So, what’s the takeaway here? For pure prediction, just grab Ridge. It’s the fastest. And trust me, when you’re wrangling a dozen models, every second counts. The study found that the overhead for Lasso and ElasticNet, especially ElasticNet with its extra grid search on the L1 ratio, is substantial. We’re talking median run times that are 167-219 times longer in some cases, all for a negligible bump in accuracy. It’s like paying for a private jet to go across town.
This is where I usually start ranting about buzzwords and marketing. “Revolutionary! Game-changing!” the PR machines scream. But here, the reality is far more grounded. The study essentially says, “Chill out, your Lasso isn’t saving you 5% on RMSE.” It’s refreshing, if a little disappointing for anyone looking for a dramatic technical reveal.
When It Actually Does Matter: Variable Selection Under Fire
Now, if you’re not just predicting, but you’re trying to figure out which variables are actually important – and you’ve got correlated predictors (multicollinearity) – then yeah, your choice suddenly becomes critical. Lasso, in particular, can fall off a cliff here. Under high correlation and low signal, its ability to correctly identify the relevant features (its recall) can plummet to a dismal 0.18. Meanwhile, ElasticNet, designed with a bit of both worlds (L1 and L2 regularization), holds steady at a much more respectable 0.93.
“For variable selection, it matters enormously, especially under multicollinearity. Lasso’s recall collapses to 0.18 under high condition numbers with low signal, while ElasticNet maintains 0.93.”
This is the real meat of the paper for anyone doing feature engineering or needing interpretability. It’s not about a few decimal points in an accuracy score; it’s about trusting your model’s insights. And if you’re dealing with messy, real-world data that’s often riddled with correlated features, picking the wrong tool can lead you down a rabbit hole of incorrect feature importance.
Who’s Actually Paying for This Research?
This is what I always ask. These aren’t abstract academic exercises. The authors explicitly ground their simulations in eight real-world production ML models from Instacart. They’re dealing with demand forecasting, conversion prediction, inventory intelligence – the kind of stuff that directly impacts the bottom line. So, the question isn’t just ‘what’s theoretically best?’ but ‘what works when you’re trying to deliver actual business value?’ Instacart is clearly investing in understanding these fundamental choices because they can translate directly into better predictions and more efficient operations.
And here’s a thought that the paper hints at but doesn’t belabor: the choice of regularization can also impact downstream processing. If you have a model that’s fantastic at selection, it might mean you can use a simpler, faster model afterward. Or, if you end up with a sparse set of features, that can simplify deployment and maintenance. It’s not just about the training run; it’s about the entire lifecycle.
The Post-Lasso OLS Red Flag
One clear loser in this study is Post-Lasso OLS. Apparently, it consistently underperforms across the board. If your goal is RMSE optimization, steer clear. It’s the only method that consistently lags. So, if you’ve been tempted by this approach, consider this a friendly, data-driven warning.
So, What Now?
Ultimately, the message from this massive simulation is one of pragmatism. For prediction, the differences are so small they’re statistically and practically insignificant for most. Focus on data quality, sample size, and model tuning. For variable selection, however, the devil is in the details, and understanding your data’s correlation structure is paramount.
It’s a good reminder that sometimes, the most complex problems have the simplest, albeit less glamorous, solutions. And sometimes, the most expensive research just confirms what many suspected: stick with the basics when they work.