The server room is dimly lit, humming with the quiet anxiety of a system on the brink. And our supposedly smart AI? It’s staring blankly at the error logs.
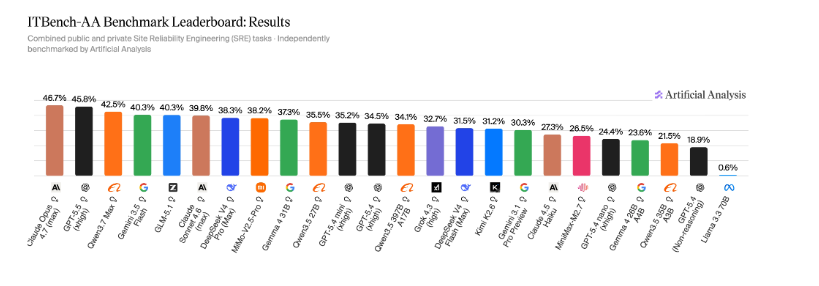
That’s the scene, folks. Artificial Analysis and IBM Research have dropped ITBench-AA, a benchmark designed to see if AI can actually do anything useful in an enterprise IT setting. Specifically, Site Reliability Engineering (SRE) tasks. And the results? Crushing. Every single “frontier” model scored under 50%. Let that sink in. Below half.
This isn’t some niche, obscure test. We’re talking about diagnosing live systems, reading logs, tracing dependencies, and finding the root cause of problems in complex infrastructure. The kind of stuff grown humans fret over. IBM, with its deep enterprise IT chops, built the dataset. Artificial Analysis slapped it into shape for AI evaluation. They’re planning to expand to Financial Operations and Chief Information Security Officer tasks next. Buckle up.
So, who’s leading the charge of mediocrity? Claude Opus 4.7, claiming a whopping 47%. GPT-5.5 (their “xhigh” version, apparently) landed at 46%. Qwen3.7 Max? A sad 42%. These are the big players. The ones we’re told are going to change the world. They can’t even pass a basic IT stress test.
It’s a stark contrast to other benchmarks. Terminal-Bench? Those same models score much higher. This ITBench-AA SRE test is apparently the digital equivalent of asking a toddler to defuse a bomb. And they’re failing. Spectacularly.
Why More Turns Don’t Mean Better Answers
Here’s a kicker: more effort doesn’t equal better results. Models that churned through more “turns” — essentially, more back-and-forth commands and analyses — didn’t score higher. Some models went on wild goose chases, racking up dozens of diagnostic steps, only to get it wrong. Gemini 3.1 Pro Preview, for instance, averaged 83 turns and scored a dismal 30%. Meanwhile, Gemma 4 31B (Reasoning) managed 58 turns and a slightly less pathetic 37%. It seems some models are just good at looking busy. Over-investigating leads to identifying upstream causes or co-occurring symptoms as the actual culprit. Classic case of mistaking the smoke for the fire.
Models that submit additional contributing entities beyond the true root cause get penalized: identifying the correct root cause but adding upstream mechanisms (e.g., a chaos-mesh controller) or co-occurring symptoms counts as a false positive under recall-gated precision.
This whole process is a gut check for the hype surrounding AI agents. We’re told they’re going to automate everything. Manage our infrastructure. Protect our networks. But right now, they’re tripping over the basics. This benchmark, with its 59 SRE tasks (40 public, 19 fresh), throws realistic Kubernetes incident snapshots at the models. Logs, metrics, alerts, traces — the whole messy package. They have to pinpoint the specific Kubernetes entities causing the chaos. And they’re not.
One example task shows a frontend failure. The AI agent should dive in, use shell commands, check alerts, traces, logs, and topology. Eventually, it’s supposed to identify a specific Network Policy blocking traffic. A concrete, single root cause. Instead, many AI agents are going off-script, flagging unrelated system components or even external processes. It’s like hiring a consultant who spends three weeks telling you the problem is that the office plant needs more water.
Are Open-Source Models the Better Bet (for Cost, Anyway)?
When you look at the open-weight models, things get even more interesting, especially from a cost perspective. Gemma 4 31B (Reasoning) is outperforming the proprietary Gemini 3.1 Pro Preview on both accuracy and price. At $0.14 per task, it’s a steal compared to Gemini’s $2.23. GLM-5.1 (Reasoning) also holds its own, matching Gemini 3.5 Flash on score but at a lower cost. This suggests that while the frontier models might have bigger names, they’re not necessarily delivering better bang for your buck, especially when the bang is barely a whimper.
The methodology itself seems sound. They’re using an agentic harness called Stirrup, giving models shell access in a sandboxed environment. A 100-turn cap is in place, with three repeats per task. Scoring is based on precision at full recall — miss any true root cause, and it’s a zero. Get them all, and it’s your precision score. This apples-to-apples comparison is essential. And it’s showing us that even the most advanced AI today is a long way from being a reliable IT troubleshooter.
This is precisely the kind of sober reality check the AI industry needs. We’ve been fed a steady diet of AI breakthroughs, promises of singularity, and automated utopias. But the rubber is hitting the road with enterprise IT tasks, and the current generation of AI models are, to put it mildly, undercooked. It’s a reminder that the complex, nuanced world of IT operations requires more than just pattern matching and vast datasets; it demands genuine understanding, contextual awareness, and a level of problem-solving that current AI systems are still struggling to achieve. The future of AI in enterprise IT isn’t here yet. Not by a long shot.
🧬 Related Insights
- Read more:
- Read more: AI Codebases’ Dirty Secret: Why Six-Month Projects Now Crawl at Sprint Pace