AI Hardware
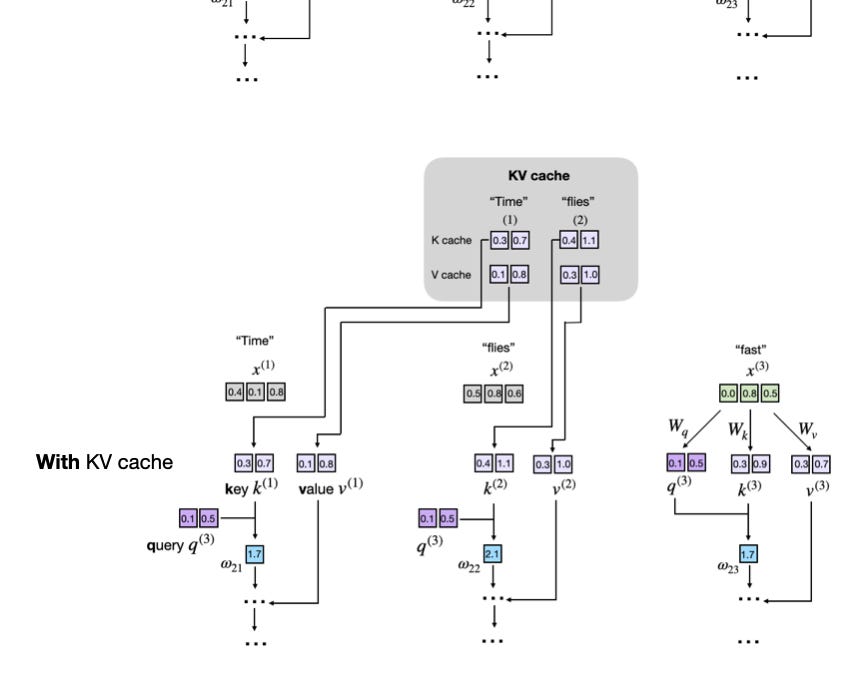
KV Caches: The Secret Sauce Making AI Chat Snappier Without Breaking the Bank
Next time your AI assistant spits out a reply in seconds, thank the KV cache—it's quietly revolutionizing how we run massive language models without melting servers. But at what memory cost?