AI Hardware
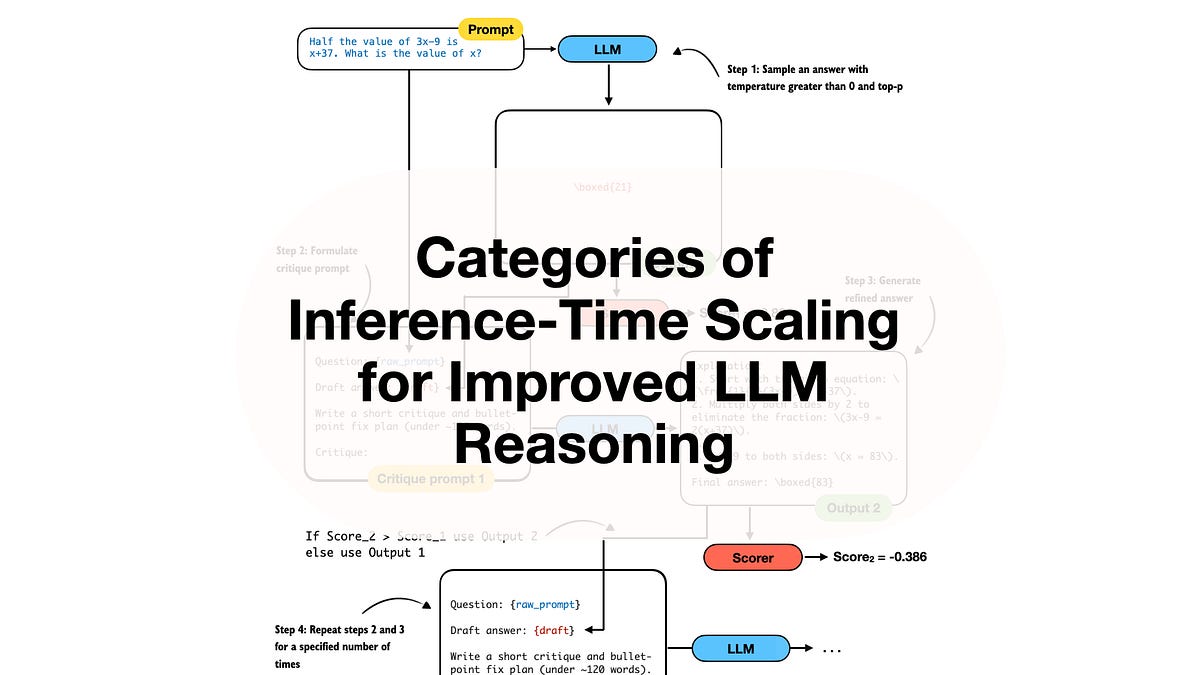
Inference Scaling: LLMs' Desperate Bid for Smarter Outputs
LLMs can't reason? No problem—just throw more compute at inference time. But is this scaling wizardry or just expensive guesswork?

