Large Language Models
Long Contexts Flip LLMs from Compute Champs to Memory Bottlenecks
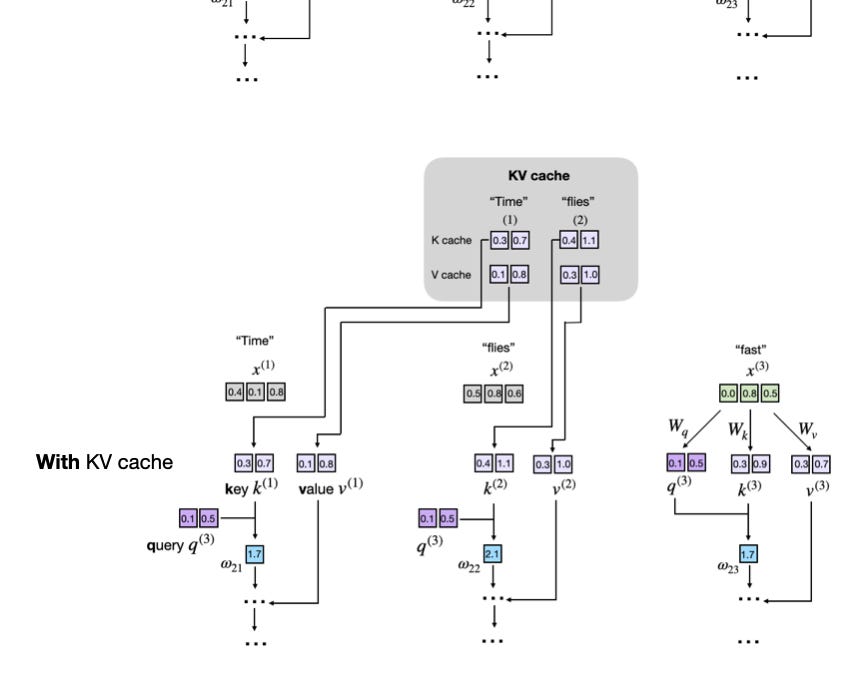
Everyone chased million-token dreams. Reality? Inference latency explodes, turning hype into hardware headaches. This shift rewrites LLM economics.