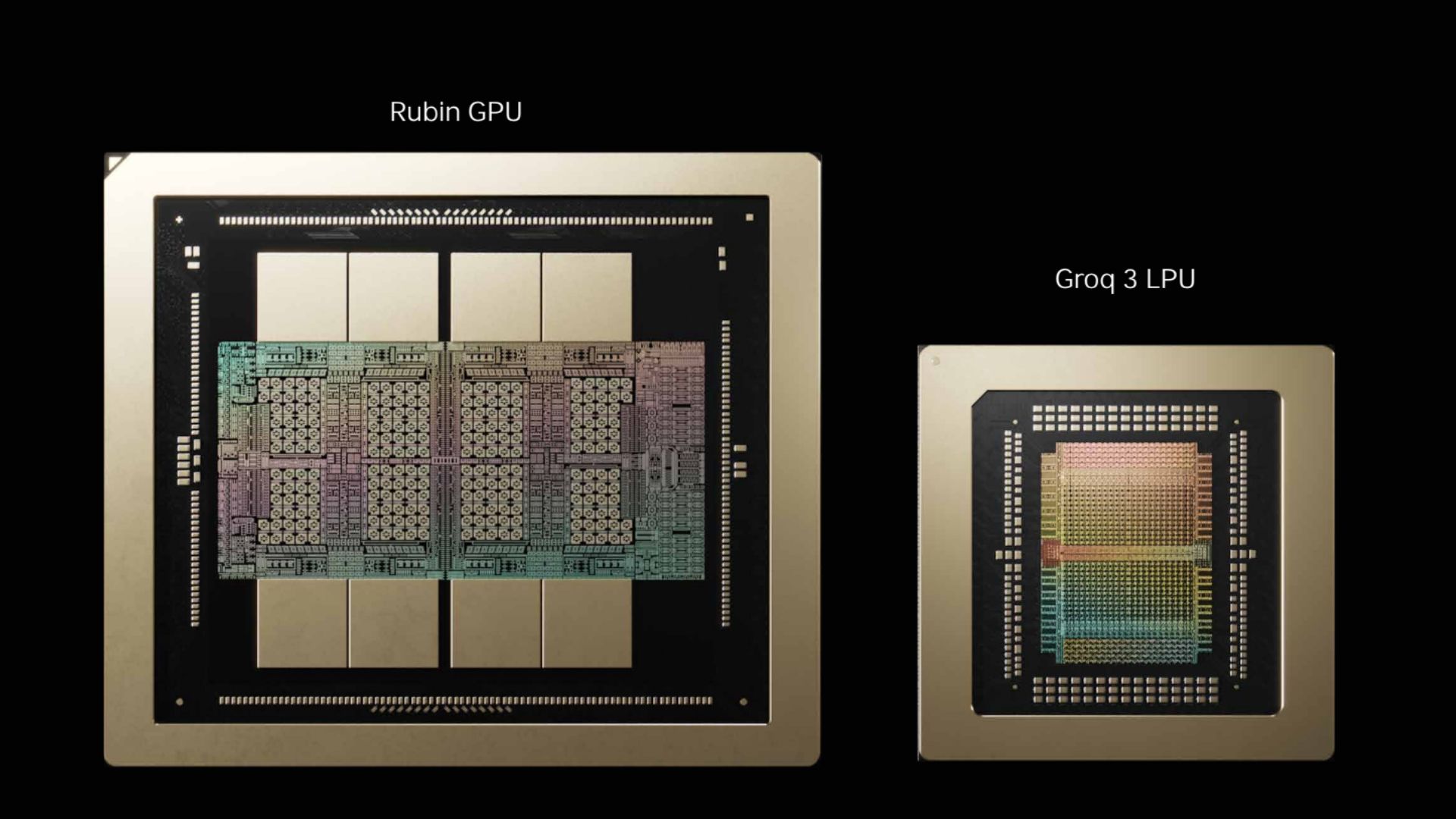
AI Hardware
AWS SageMaker Locks in GPUs for AI Inference—Ending the Capacity Nightmare
GPU shortages derailed 35% of enterprise AI inference projects last year. AWS SageMaker's new training plans fix that—reserving p-family instances just for endpoints.