Vector Databases Explained: How They Power Modern AI Applications
A comprehensive guide to vector databases, covering how they store and search high-dimensional embeddings, their role in RAG and recommendation systems, and how to choose the right one.
⚡ Key Takeaways
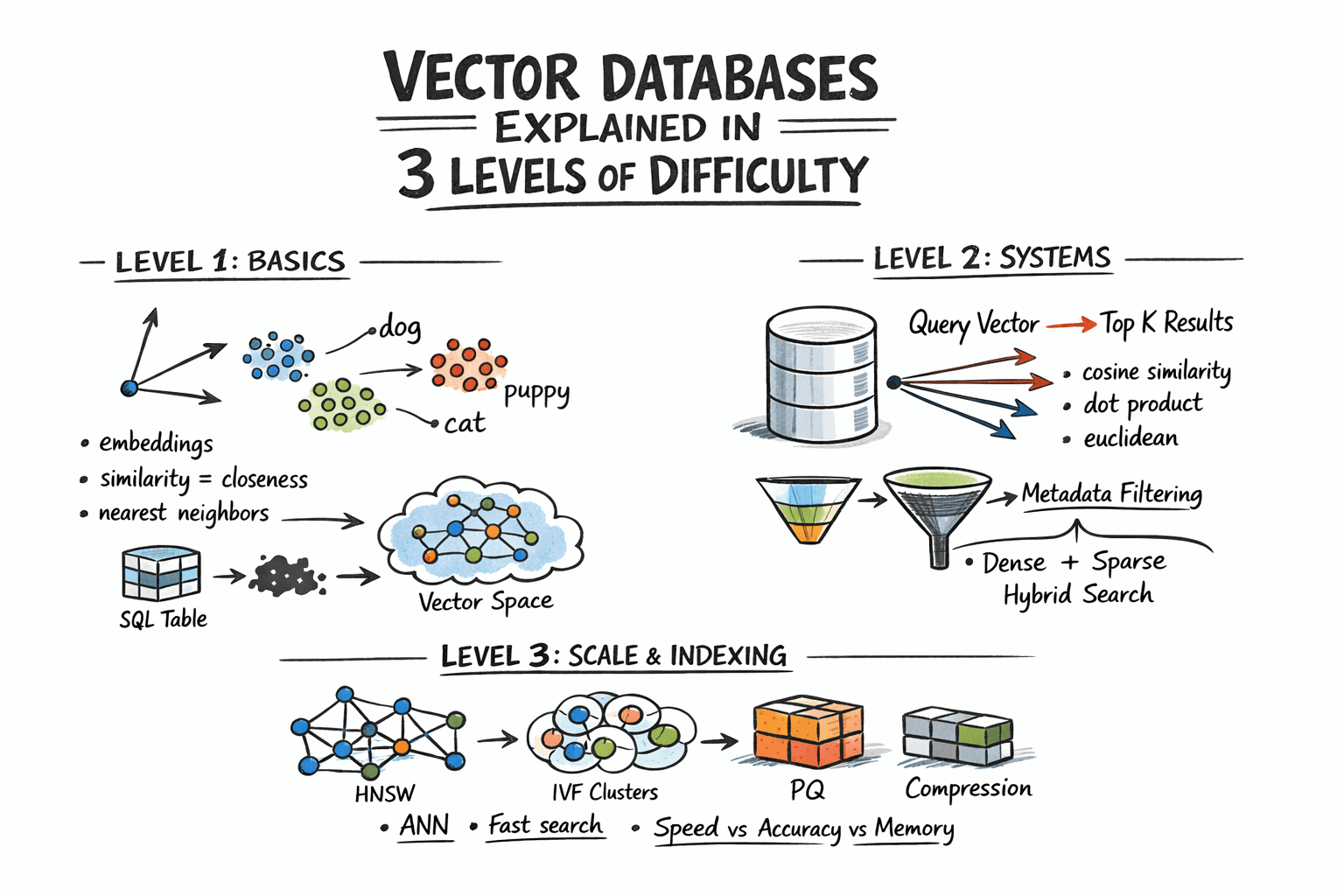
- {'point': 'ANN algorithms make similarity search practical at scale', 'detail': 'Algorithms like HNSW and IVF trade small accuracy reductions for massive speed improvements, enabling sub-millisecond searches across millions of vectors.'} 𝕏
- {'point': 'RAG quality depends directly on retrieval quality', 'detail': "In retrieval-augmented generation pipelines, the vector database's ability to find the most relevant document chunks determines whether the LLM's response will be accurate and helpful."} 𝕏
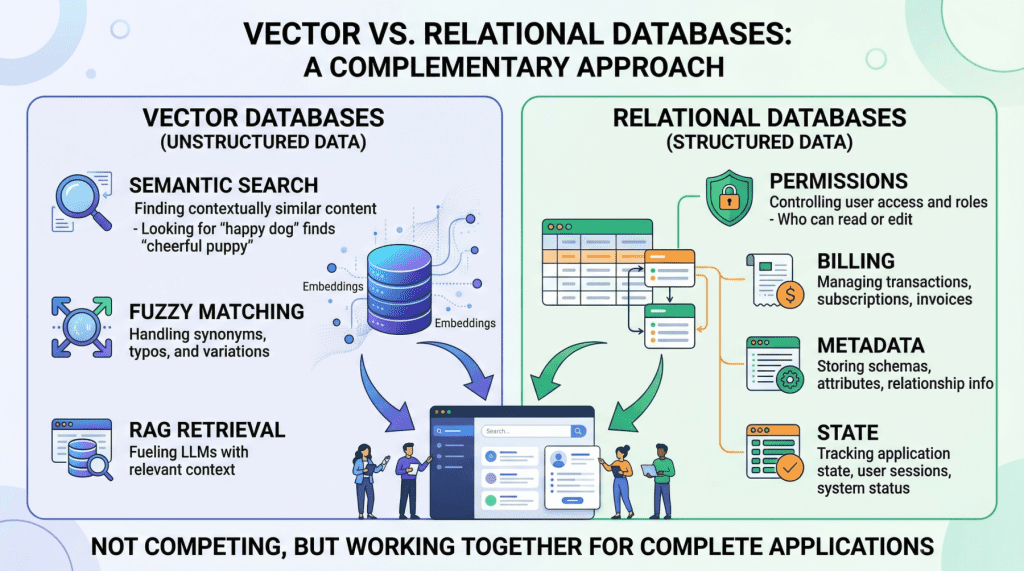
- {'point': 'Choose based on scale and operational needs', 'detail': 'pgvector works for smaller datasets within existing PostgreSQL stacks, while purpose-built databases like Pinecone, Milvus, and Weaviate are necessary for large-scale production workloads.'} 𝕏
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Related Stories
AI Tools
Vector Databases: The Cosmic Map Turning AI's Fuzzy Dreams into Laser-Focused Reality

AI Tools
$50 Billion Vector Database Empire: Built on the Wrong Question

AI Tools
Databases: From SQL Dinosaurs to Vector Hype Machines
AI Tools