LLM Evaluations: Four Flawed Pillars Propping Up AI Hype
LLM benchmarks promise objectivity. They're mostly marketing mirrors reflecting what sells models, not what works.
⚡ Key Takeaways
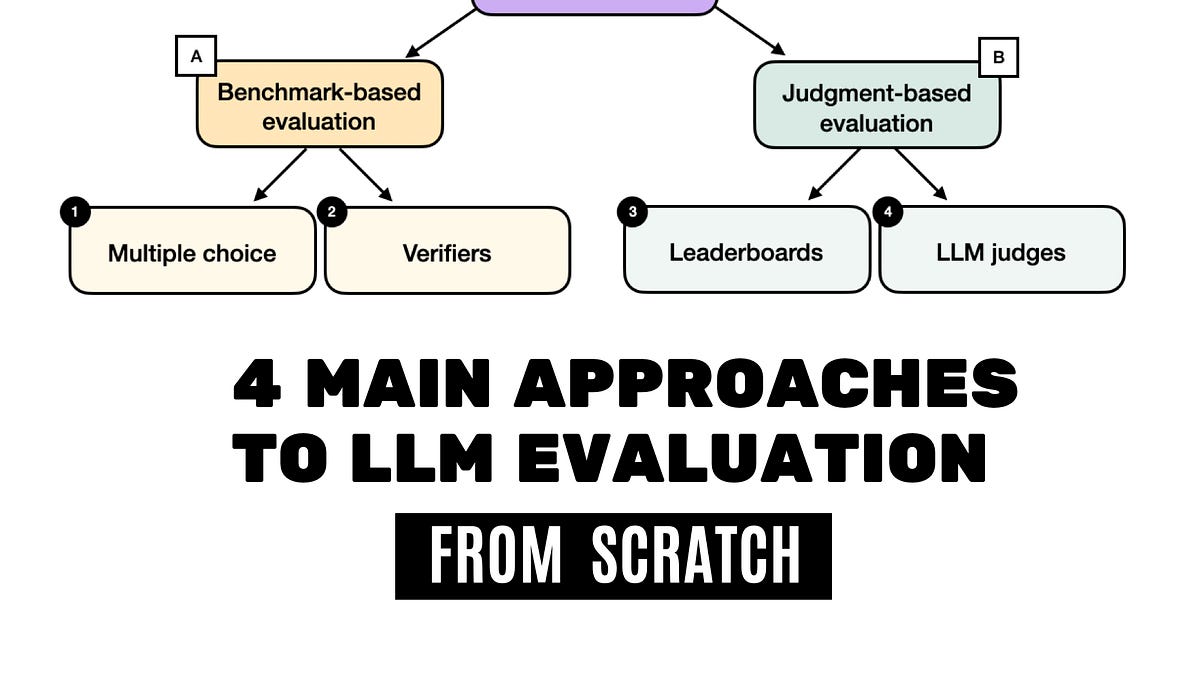
- Multiple-choice benchmarks test recall, not real reasoning — easy to game.
- Leaderboards drive hype and downloads but crumble under contamination.
- All four methods distract from production metrics; follow the money trail.
🧠 What's your take on this?
Cast your vote and see what theAIcatchup readers think
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by Ahead of AI
Related Stories

AI Hardware
Arcee AI's 400B Sparse MoE Cracks Open Agentic AI — #2 on PinchBench, Just Behind Claude

AI Hardware
Screenshot-Seeking AI Agents: The Desktop Automation Savior That Actually Delivers

AI Hardware
Local AI Judged My WhatsApp Friends—And Exposed How Shallow We All Are

AI Hardware