KV Caches: The Secret Sauce Making AI Chat Snappier Without Breaking the Bank
Next time your AI assistant spits out a reply in seconds, thank the KV cache—it's quietly revolutionizing how we run massive language models without melting servers. But at what memory cost?
⚡ Key Takeaways
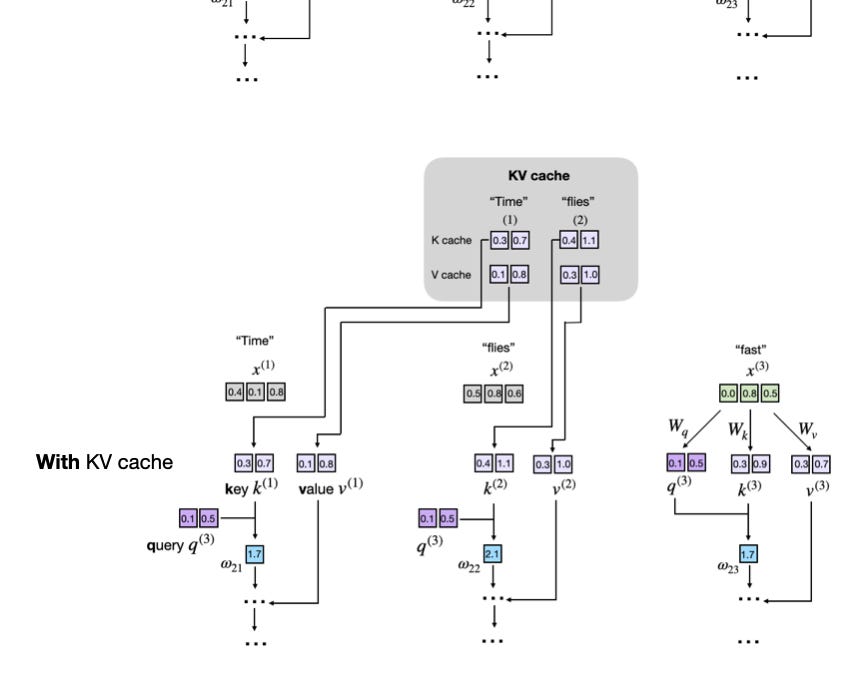
- KV caches cut inference redundancy by reusing past keys/values, speeding generation 5-10x.
- Tradeoff: Explodes memory use, unfit for training.
- Core to production LLMs; paves way for million-token contexts if optimized.
🧠 What's your take on this?
Cast your vote and see what theAIcatchup readers think
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by Ahead of AI
Related Stories

Large Language Models
Red Hat's llm-d Splits LLM Inference in Two — And IBM Fusion HCI Makes It Stick

Large Language Models
Long Contexts Flip LLMs from Compute Champs to Memory Bottlenecks

AI Hardware
Arcee AI's 400B Sparse MoE Cracks Open Agentic AI — #2 on PinchBench, Just Behind Claude
AI Hardware