TII's Falcon Perception: The 600M Transformer That Fuses Vision and Language from Layer Zero
Image patches and text tokens slam together in the first layer—no more Lego-block vision models. TII's Falcon Perception proves a single stack can outthink modular giants.

⚡ Key Takeaways
- Falcon Perception's early-fusion Transformer unifies vision-language processing from layer zero, ditching modular bottlenecks.
- Outperforms SAM 3 dramatically on semantic complexity (e.g., +21.9 spatial points) via PBench benchmark.
- Optimizations like Muon, FlexAttention, and 685GT training enable efficient scaling to dense, real-world perception.
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by MarkTechPost
Related Stories

Large Language Models
r/programming's LLM Blackout: Coders Draw a Line in the Sand
Large Language Models
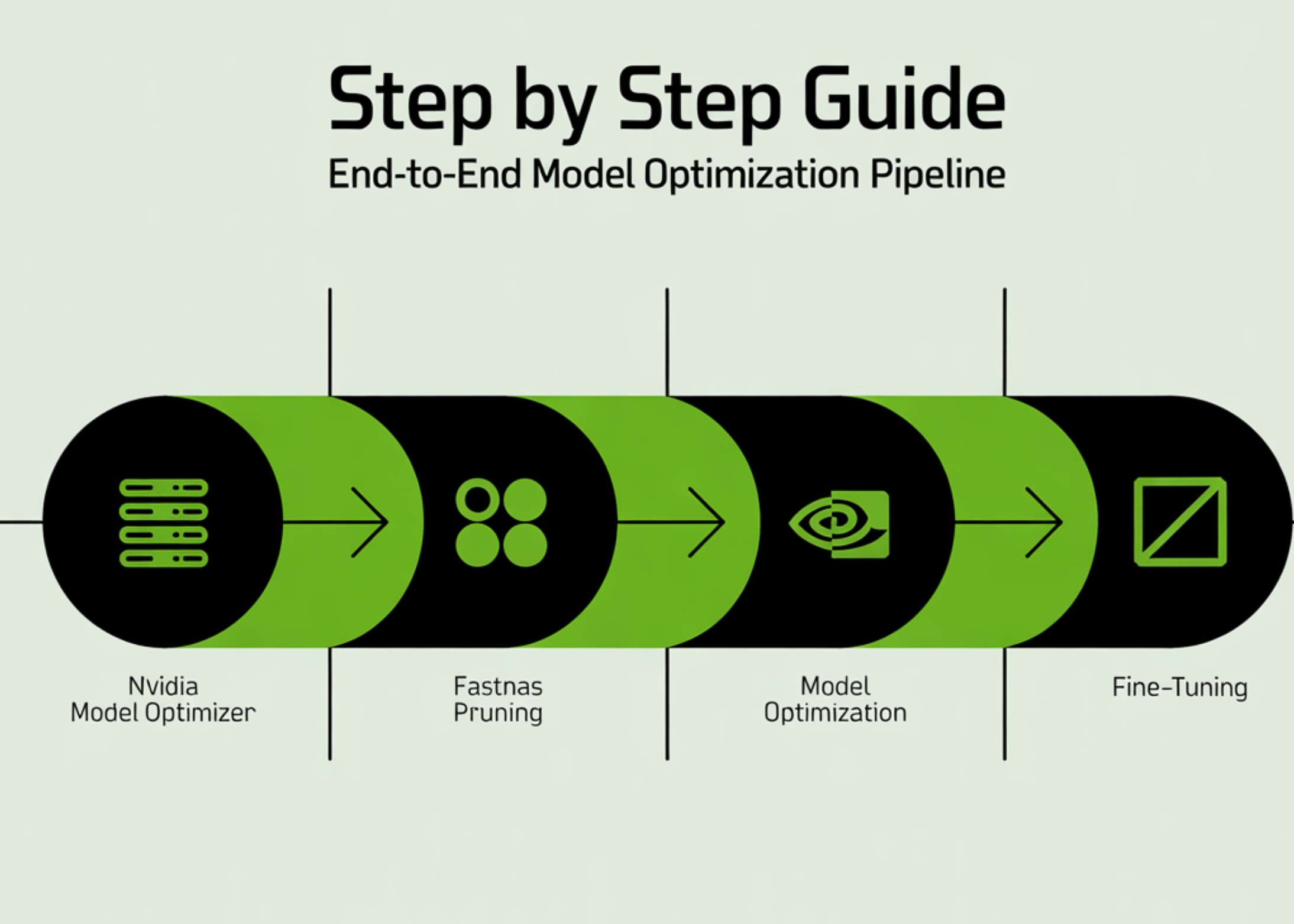
I Pruned a ResNet with NVIDIA's Model Optimizer in Colab – Hype Meets Reality

Large Language Models
Gemma 4's 31B Crushes Rivals 20x Its Size — But Who's Cashing In?

Large Language Models