LLM Architectures: Seven Years of Transformer Tinkering
Seven years post-GPT, LLMs look suspiciously similar. DeepSeek V3's bells and whistles? Mostly hype. Here's why evolution feels like a stall.
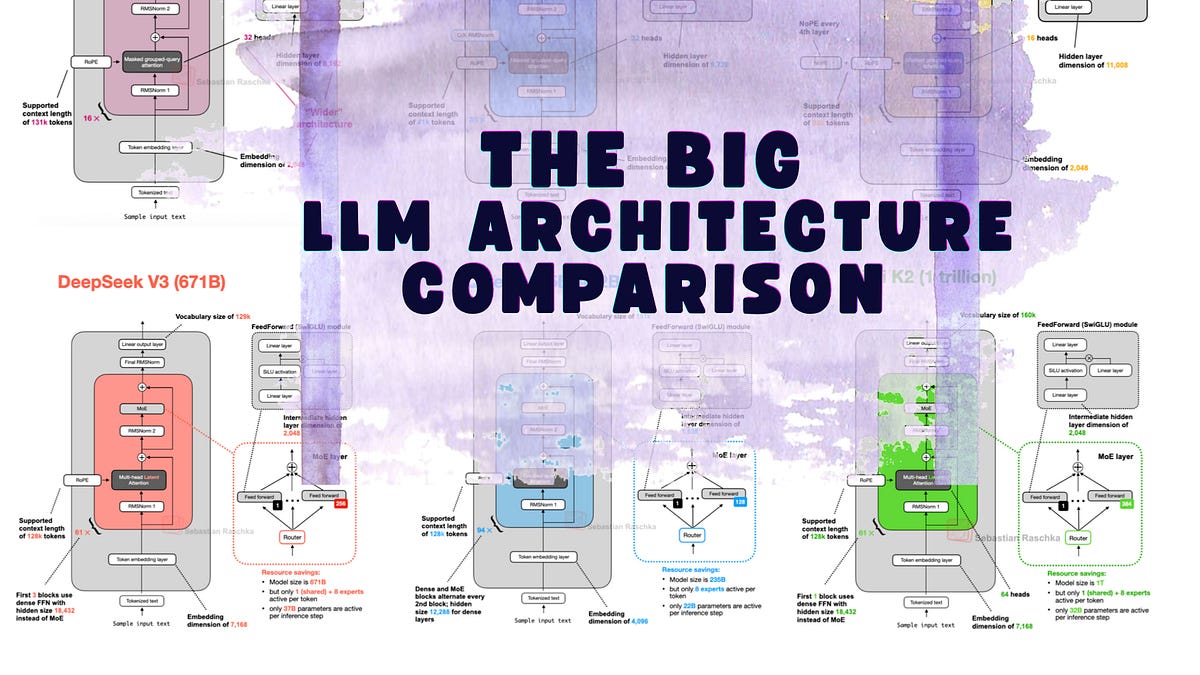
⚡ Key Takeaways
- LLM architectures evolved little since GPT-2: mostly efficiency tweaks.
- DeepSeek V3's MLA and MoE shine for inference, but no paradigm shift.
- Hype oversells; data and training matter more than structure.
🧠 What's your take on this?
Cast your vote and see what theAIcatchup readers think
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by Ahead of AI
Related Stories

AI Hardware
Arcee AI's 400B Sparse MoE Cracks Open Agentic AI — #2 on PinchBench, Just Behind Claude

AI Hardware
Screenshot-Seeking AI Agents: The Desktop Automation Savior That Actually Delivers

AI Hardware
Local AI Judged My WhatsApp Friends—And Exposed How Shallow We All Are

AI Hardware