Mixtral to DoRA: 2024's Opening AI Papers That Rewired LLMs
January's Mixtral 8x7B proved sparse MoEs can outpace dense giants like Llama 2 70B. Six papers from H1 2024 reveal smarter paths forward, not just bigger models.
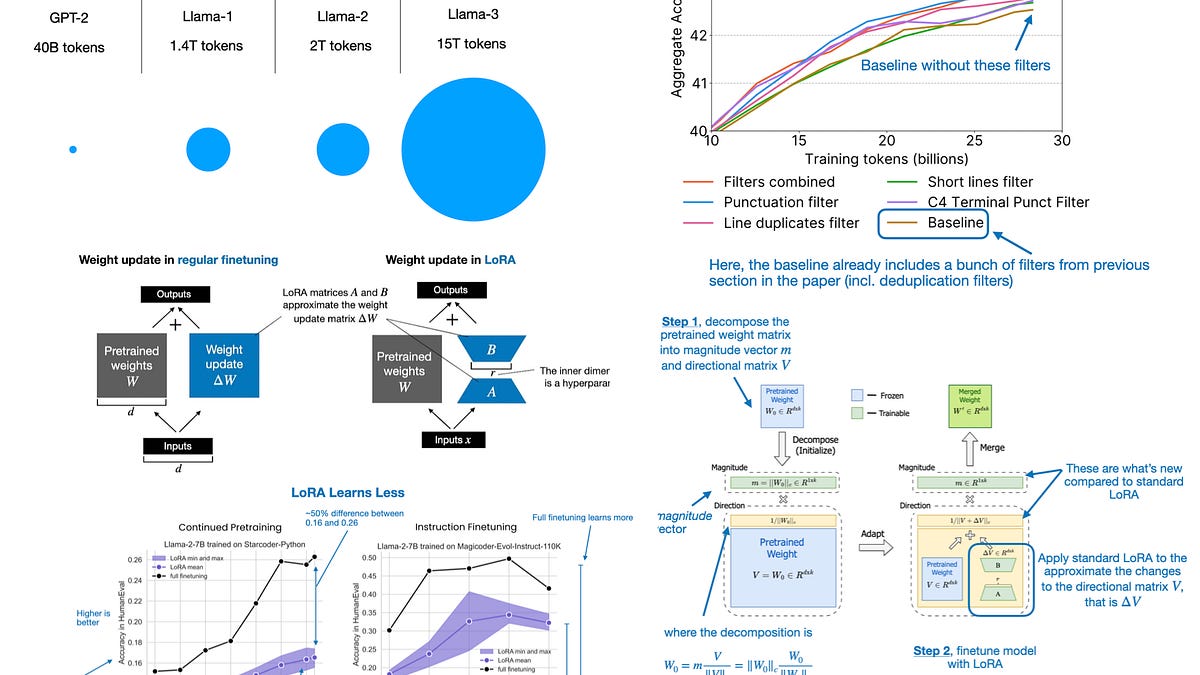
⚡ Key Takeaways
- Mixtral 8x7B pioneered open MoE, beating 70B dense models with 13B active params.
- DoRA refines LoRA by decomposing weights, boosting fine-tuning by 2-5% on benchmarks.
- H1 2024 papers prioritize efficiency, signaling shift from raw scale to smart architectures.
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by Ahead of AI
Related Stories

AI Hardware
Arcee AI's 400B Sparse MoE Cracks Open Agentic AI — #2 on PinchBench, Just Behind Claude

AI Hardware
Screenshot-Seeking AI Agents: The Desktop Automation Savior That Actually Delivers

AI Hardware
Local AI Judged My WhatsApp Friends—And Exposed How Shallow We All Are

AI Hardware