Long Contexts Flip LLMs from Compute Champs to Memory Bottlenecks
Everyone chased million-token dreams. Reality? Inference latency explodes, turning hype into hardware headaches. This shift rewrites LLM economics.

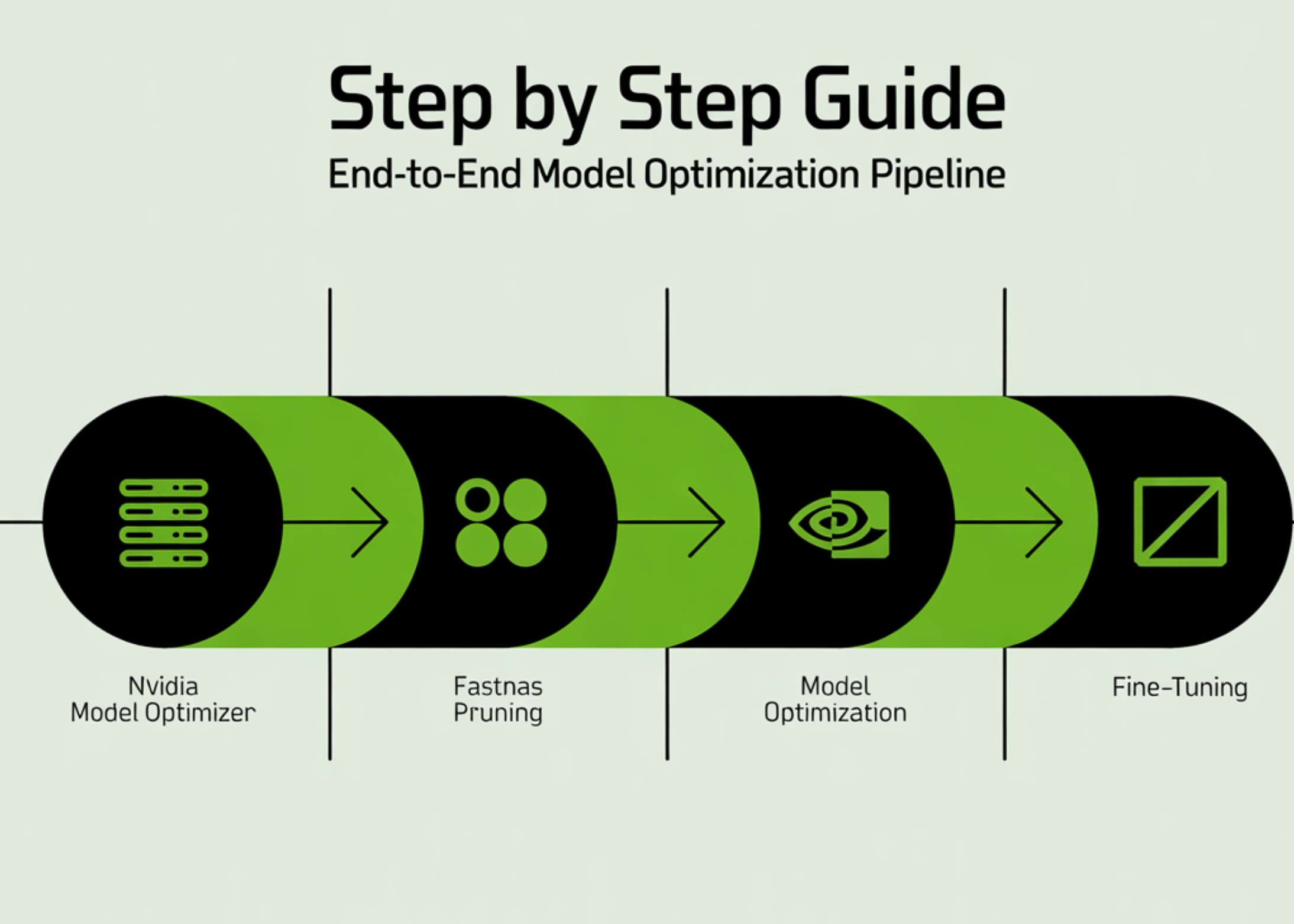
⚡ Key Takeaways
- LLM inference flips memory-bound past 8-32k tokens due to quadratic KV cache growth.
- Latency spikes 10-20x at 128k, gutting throughput and raising costs.
- Fixes like FlashAttention help, but sparse models or new hardware needed for true long-context scaling.
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by Towards AI
Related Stories

Large Language Models
Supermicro Co-Founder's Bold Not Guilty Plea in $2.5B Nvidia AI Server Smuggle to China

Large Language Models
r/programming's LLM Blackout: Coders Draw a Line in the Sand

Large Language Models
TII's Falcon Perception: The 600M Transformer That Fuses Vision and Language from Layer Zero
Large Language Models