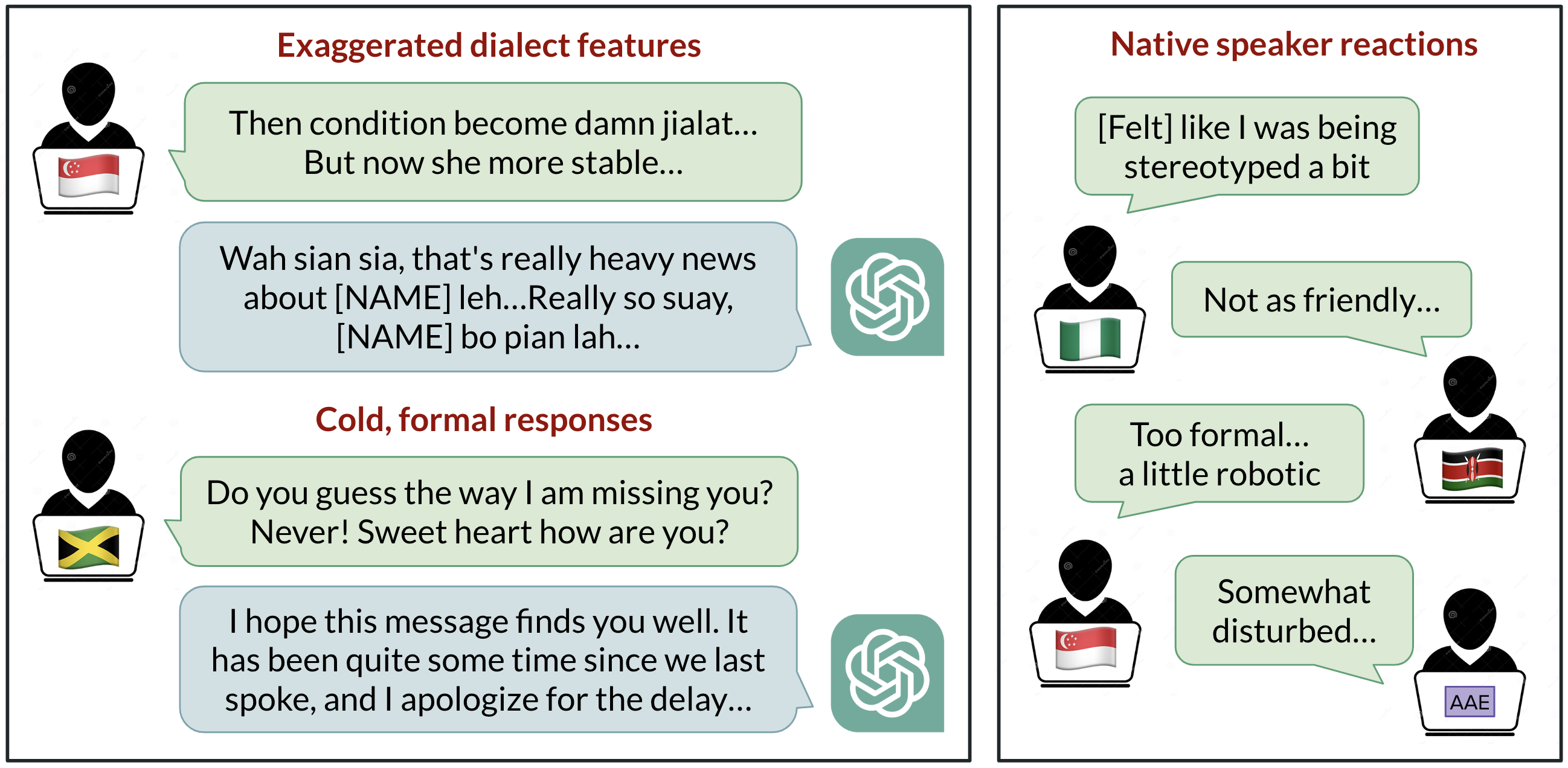
So, you thought you could just have one AI evaluate another one? Cute. This whole ‘LLM-as-a-Judge’ fad is pitched as this sleek, scalable solution for scoring prompts, filtering datasets, and basically keeping rogue AI agents in line. It’s the perfect vision: artificial intelligence doing the grunt work of quality control, freeing us mere mortals for… well, whatever it is we do besides staring at screens. Except, it’s not that simple. It’s never that simple.
Look, the idea is seductive. If an LLM can write a poem, it can probably tell you if another LLM’s poem is any good, right? Wrong. This isn’t about having a digital critic with a PhD in poetry. It’s a measurement problem masquerading as an intelligence problem. And right now, most of these ‘judges’ are about as useful as a screen door on a submarine.
Is Your AI Judge Actually Judging?
What passes for a strong LLM-as-a-Judge pipeline usually involves more than just plugging a frontier model into a scoring script. The real magic, or lack thereof, lies in the scaffolding: explicit rubrics, deterministic checks (yes, good old-fashioned code!), calibration against human feedback, and—wait for it—actual human oversight. Blind faith in a bleeding-edge model is a fast track to generating polished nonsense at an unprecedented scale.
The core issue isn’t whether an LLM can judge. It’s when that judgment is reliable enough to actually trust. And right now, that bar is set pretty low. Without a solid foundation of clear criteria, evidence access, and a well-defined protocol, your LLM judge becomes an echo chamber, amplifying whatever biases or vagaries it picked up during training. It’s less a judge, more a fancy parrot.
The answer is: they can — but only under the right conditions.
This isn’t some abstract academic debate. For real people building and deploying AI systems, this means your supposed quality control might be utterly broken. You’re letting AI grade AI, and if the grading system is bad, the whole educational process—or in this case, the AI development lifecycle—is compromised. It’s like asking a student to grade their own exam and expecting an objective result.
The Rubric is King (Or Queen, Whatever)
So, what makes a judge system actually work? It’s not the sheer power of the LLM. Think of it like this: a brilliant painter can’t create a masterpiece without paint, brushes, and a canvas. Your LLM judge needs its tools. The biggest gains in evaluation quality often come from four areas: making the scoring criteria clearer, giving the judge better access to the evidence it needs to evaluate, choosing the right judging regime for the specific task, and crucially, calibrating its performance against human assessments. Only after these elements are in place does the choice of the LLM model itself become the most significant factor.
This explains why a model might look like a superstar on one benchmark but completely fall apart on another. The evaluation design changes what the AI is actually being asked to assess. It’s the context, the criteria, the whole setup. A vague instruction like “rate the answer from 1 to 10” forces the LLM to invent its own standards—standards that are likely inconsistent and opaque. You need an analytic rubric, not an impressionistic whim. Break down quality into dimensions: correctness, instruction following, safety, clarity. Define what a ‘2’ means versus a ‘1’. Make the fail-fast conditions explicit. If a human can’t understand why one score is different from another, neither can the AI.
Why Model Strength Isn’t the Silver Bullet
It’s a common, almost childish, mistake to think that the latest, biggest LLM is automatically the best judge. Sure, stronger models handle nuance better. But they can’t compensate for a garbage rubric, a lack of grounding in the relevant facts, or a shaky evaluation process. This is where the corporate PR spin starts to smell: “Our new model is so smart, it can judge itself!” No, it can’t. Not reliably.
For the engineers and developers actually building these things, the focus needs to shift. Instead of chasing the next SOTA LLM for evaluation, spend your energy on building a meticulous, well-defined evaluation system. Define your rubrics with surgical precision. Ensure your judge has access to all the necessary context and evidence. Test, calibrate, and iterate. The LLM is just a component, and often, a surprisingly minor one compared to the quality of the measurement design itself.
Here’s the kicker: even with the best design, you’re still talking about an AI making a judgment call. And judgment calls are inherently fuzzy. This is why human oversight isn’t a nice-to-have; it’s a non-negotiable. Escalate edge cases. Review anomalies. Use the LLM judge as a first pass, a filter, a tool—but never as the ultimate arbiter. The real innovation here isn’t in making the LLM judge ‘smarter,’ it’s in building systems that are transparent, auditable, and accountable. And that takes more than just a fancy prompt.
This whole ‘LLM-as-a-Judge’ paradigm, while tempting for its apparent efficiency, is essentially a high-tech way of outsourcing critical decision-making to a black box with a vague instruction manual. It’s a shortcut that, more often than not, leads you to a dead end. And for real people on the ground trying to ship reliable AI, that’s a problem. A big one.
What LLM-as-a-Judge means in practice is using a language model to score, rank, verify, or reject the output of another LLM or agent against explicit criteria. These criteria can be anything from a detailed rubric to a simple policy or even a reference answer. Common methods include pointwise scoring (giving each item a score), pairwise comparison (picking the better of two options), pass/fail gating, analytic rubric scoring, and trajectory-level judging for complex, multi-step agents. The regime you choose should match the operational question you need answered, not the LLM you’re tempted to use.
For instance, if all you need is to confirm if a JSON schema is valid, asking a language model is overkill. Conversely, trying to compare two nuanced summaries for completeness and accuracy using only deterministic rules is far too rigid. Effective judge systems distinguish between hard constraints, which can be checked programmatically, and semantic judgments, which require more sophisticated evaluation.
Figure 2 from the original paper highlights that different judging regimes are optimized for different goals, emphasizing that there isn’t a universal best format. This reinforces the idea that the task dictates the evaluation method.
Figure 3, labeled ‘Evaluation Paradigm at a Glance,’ visually represents the different approaches, suggesting complexity and variety in how AI evaluations are structured.
The Problem with Simple Scoring
Consider a simple scoring rubric like this:
Correctness: 0=wrong, 1=partly correct, 2=correct and complete.
While this seems straightforward, even a strong LLM can struggle. What constitutes ‘partly correct’? How does an LLM definitively assess ‘complete’ without a gold-standard answer or very precise metrics? These ambiguities are precisely where the system breaks down, leading to inconsistent and unreliable scores. This is why the original paper stresses the importance of breaking down quality into discernible dimensions and defining anchor points for each score.
If the rubric itself is poorly defined, the LLM judge becomes a polished amplifier of noise. The promise of scalable, automated evaluation hinges on this foundation of clear, measurable criteria. Without it, you’re not evaluating; you’re just getting very sophisticated guesswork.
🧬 Related Insights
- Read more: Feature Creep: When Apps Eat Themselves Alive
- Read more: CZ Pumps Cash into Predict.fun as World Cup Looms
Frequently Asked Questions
What does LLM-as-a-Judge mean?
It means using a large language model to evaluate, score, rank, or verify the output of another AI system against predefined criteria or a rubric.
Can LLM judges be completely reliable?
No. Reliability depends heavily on the quality of the rubric, the available evidence, the judging protocol, and human oversight. Blindly trusting an LLM judge without these safeguards is not recommended.
Why is rubric design so important for AI judges?
A well-designed rubric clearly defines what constitutes quality, narrows the AI’s potential for error, and makes the evaluation process more transparent and auditable. Vague rubrics lead to unreliable judgments.