Why AI Chats Crawl on Long Prompts: KV Cache, Prefill, and the Decode Trap
That endless wait when you paste a novel into ChatGPT? It's not just 'thinking'—it's LLM inference hitting a memory wall. Here's the inside story on KV cache and why it changes everything.

⚡ Key Takeaways
- LLM inference splits into prefill (parallel prompt crunch) and decode (sequential generation loop)—decode's where slowdowns hide. 𝕏
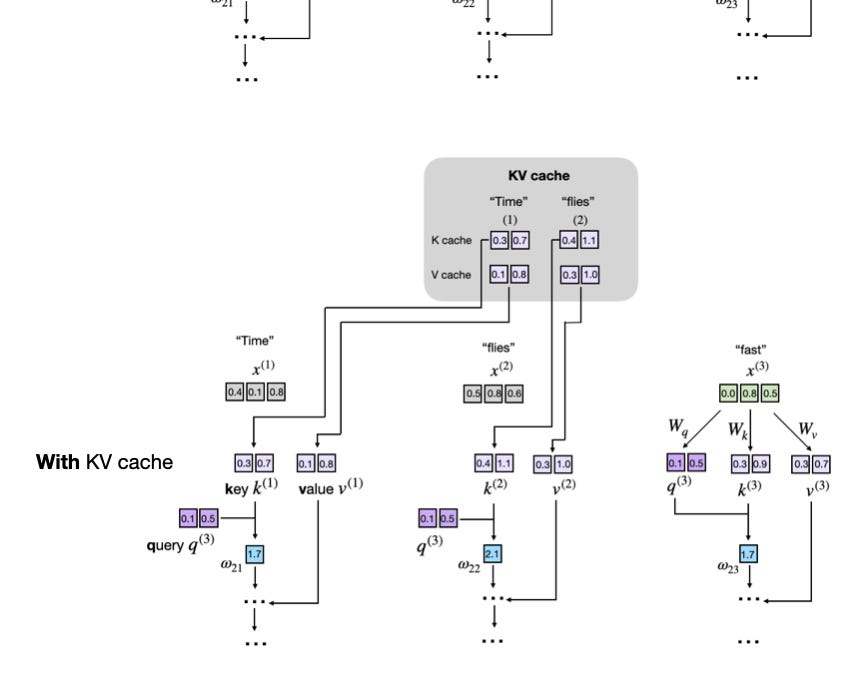
- KV cache stores keys/values to avoid recomputing history, but growing contexts crush memory bandwidth. 𝕏
- Future fixes like custom chips promise blazing inference, enabling always-on, infinite-context AI for everyone. 𝕏
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by Towards AI
Related Stories
Large Language Models
Google's TurboQuant: 6x LLM Compression That Doesn't Sacrifice Speed
Large Language Models
KV Caches: The Hidden Speed Boost Powering Your Daily AI Chats

AI Research
TurboQuant's 6x KV Cache Slash: The Inference Efficiency Leap No One Saw Coming

Large Language Models