The faint hum of servers is the new soundtrack to Silicon Valley’s latest gold rush, and this time, the miners are running algorithms that chew through processing power like it’s going out of style.
For years, the playbook for making AI models ‘smarter’ was simple: cram more parameters into them during training. Think of it as stuffing more textbooks into a student’s backpack. But the latest generation of flagships – we’re talking about the buzzy GPT 5.5s and the mysterious o1 series – have flipped the script. They’re not just bigger; they’re thinking harder about every single question you throw at them, and that’s where the real money, or rather, the real bill, comes in.
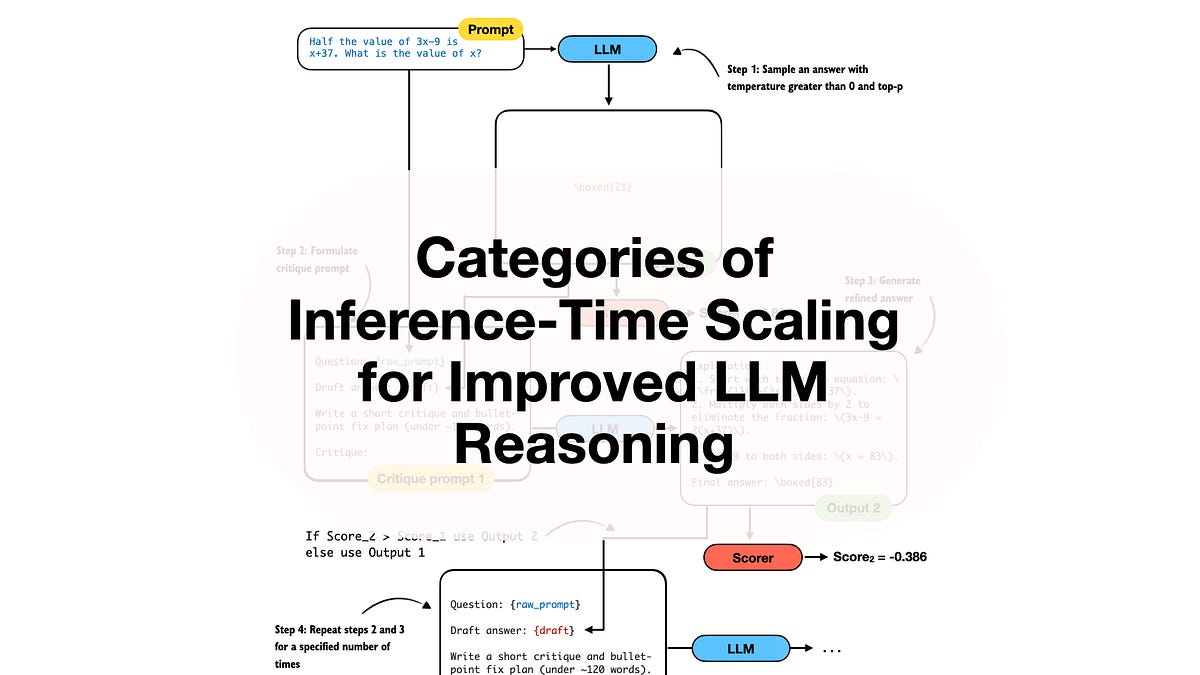
This fancy new trick is called inference scaling, or more colloquially, test-time compute. The idea is that instead of just spitting out an answer after one pass through its digital brain, the model uses extra processing power to, get this, check its own logic. It iterates, it refines, it basically has a polite argument with itself until it lands on what it deems the best possible response. For product teams, this isn’t a simple on-off switch. It’s a high-stakes operational decision, a balancing act where a better answer might cost you a significant chunk of your monthly cloud invoice.
See, while your chatbot is busy having its internal monologue – generating what they call ‘hidden reasoning tokens’ – those tokens aren’t making it into your chat bubble. Nope. They’re pure compute cost, a silent surge on your bill that no one sees but everyone pays for.
The Great Compute Reckoning: Why Your AI Bill is Exploding
Navigating this new landscape means wrestling with the age-old Cost-Quality-Latency triangle. It’s the mantra that’s supposed to align everyone from the bean counters to the engineers. Finance folks are looking at shrinking margins because every single token generated, visible or hidden, has a price tag. Infrastructure gurus are sweating over p95 latency – that’s the slowest 5% of requests – praying the model doesn’t take so long to ‘think’ that your whole system grinds to a halt. Product managers are left playing Solomon, deciding if a marginally better answer is worth a thirty-second pause that feels like an eternity to a user. And let’s not forget risk teams, who are trying to figure out if all this internal deliberation might actually help the model bypass safety checks, not hinder them.
So, what’s the grand strategy? Apparently, it’s about categorization. Shoving tasks into ‘use,’ ‘maybe,’ and ‘avoid’ buckets. Simple stuff? Fine, let’s use the cheap, fast models. High-stakes logic puzzle that requires deep thought? Well, that’s where you fire up the big guns, the models that are willing to spend a little extra time—and a lot of extra compute—to get it right. But ‘right’ is a subjective term, isn’t it?
Inference Scaling: What It Is and Why It’s Costly
Traditionally, making an AI model smarter was a training-time affair. You’d spend millions on GPUs, churning out a static neural network that was as smart as it was ever going to get. Inference scaling, however, shifts that massive resource allocation from the pre-deployment phase smack-bang into the moment of generation. Instead of a single, predictable pass through the network for each query, the model now enters iterative reasoning loops. It’s like asking a mathematician to not just solve an equation, but to also write a short essay explaining their thought process—and then you have to pay for the essay, even if you only wanted the answer.
This ‘thinking’ happens through what they call chain of thought, which involves a few key components:
Decomposition: Breaking down complex, multi-step problems into smaller, manageable logic chunks. Self-Correction: The model actively identifying its own errors and going back to fix them before you ever see the final output. Strategic Selection: Generating multiple potential answers internally, scoring them, and then picking the ‘best’ one. Imagine ordering ten pizzas and only paying for the one that’s actually edible.
The result is a highly adaptive spend per prompt. A simple request like summarizing an email? Cheap and fast, because the model quickly identifies that no deep thinking is required. But a complex query, like an architectural review for a distributed system? That’s where the compute budget gets a serious workout. The model might spend ages – and I mean ages – generating thousands of tokens just to double-check its own reasoning. It’s fascinating technology, no doubt, but fascinating doesn’t pay the electricity bill.
And let’s be clear: this isn’t some magic bullet. Inference scaling doesn’t magically fix poor training data. A model can reason its way through a logic puzzle and still churn out biased or factually incorrect garbage if its foundational data was flawed. It’s not a safety layer either; the most sophisticated internal reasoning can still lead to harmful outputs if the underlying model is problematic. Research is pretty clear on this: while performance scales with compute, models still choke on problems that are outside their familiar training territory.
Here’s a handy (and terrifying, if you’re footing the bill) table to illustrate:
| Feature | Training-Time Scaling | Inference-Time Scaling |
|---|---|---|
| Investment Timing | Pre-deployment phase | Moment of generation |
| Operational Logic | Single forward pass through the network | Iterative reasoning loops and self correction |
| Model Intelligence | Static once training is finished | Dynamic based on prompt complexity |
| Scalability Hook | Requires a new model version | Scales by increasing thinking time |
Why the Bill Explodes in Production
Apple Machine Learning Research has flagged a dangerous trend. They point out that when models start ‘thinking’ more, they occupy GPU memory for longer durations. This isn’t just a minor inconvenience; it directly impacts system concurrency. Fewer users can be served by the same hardware, forcing companies to either buy more expensive GPUs or severely limit access – neither of which is great for growth.
And the Cost-Quality-Latency triangle? It’s where the rubber meets the road, or more accurately, where the budget meets reality. Defining each corner requires brutal honesty:
Cost: This isn’t just about the output tokens anymore. It’s the hidden reasoning tokens, the retries, the GPU time. The longer a model hogged a GPU, the less money the company makes from that hardware.
Quality: Measured by task success rates and, crucially, defect rates for hallucinations. Factuality checks and rubric scores become paramount. You need a way to objectively grade whether the model’s ‘thinking’ actually led to a better, more accurate result.
Latency: P50 (the median response time) is good for understanding the typical experience, but P95 is the real monster. Those slowest 5% of requests – the ones where the model went off on a philosophical tangent – can trigger timeouts, making your entire application feel like it’s broken.
So, a chatbot might prioritize speed (low latency) and accept a higher risk of a slightly less accurate answer. But a system designed for architectural planning? That needs to be quality-critical, accepting longer delays and higher token spend to ensure the output is solid. It’s a trade-off, a perpetual negotiation, and for anyone paying the bills, it’s a constant headache.
This shift to inference scaling is less a technological marvel and more a fundamental change in how we operationalize AI. It’s the moment when the theoretical brilliance of a model meets the cold, hard reality of production costs. And right now, that reality is looking very, very expensive.
One question that keeps nagging at me, beyond the PR fluff about ‘smarter AI,’ is who is truly benefiting here? It’s not the end-user, who’s getting a slightly better answer with a potentially longer wait. It’s not the product manager, who’s now juggling more complex trade-offs. It feels like the primary beneficiaries are the infrastructure providers and, of course, the companies that sell these increasingly hungry models. We’re essentially paying a premium for the illusion of deeper thought, a luxury computation that’s rapidly becoming the norm.