Hugging Face's TRL v1.0: Post-Training's New Overlord or Just More Hype?
Ever wondered why fine-tuning LLMs still feels like black magic? Hugging Face's TRL v1.0 swears it's got the fix—with a CLI that might actually work.
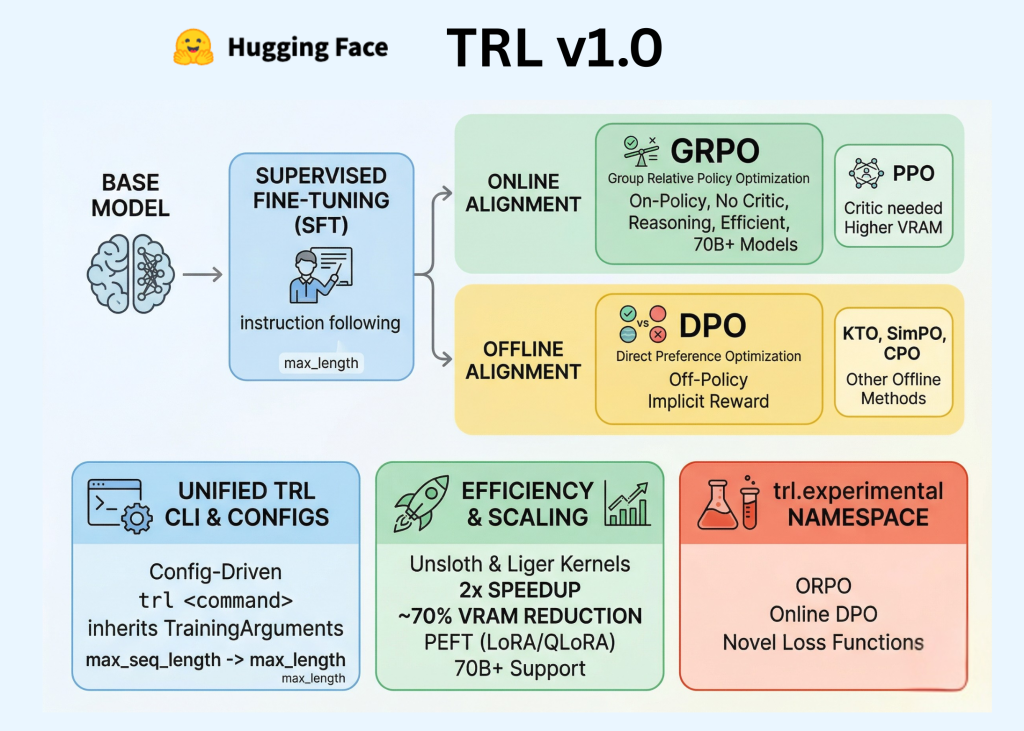
⚡ Key Takeaways
- TRL v1.0 unifies SFT, reward modeling, and alignment with a slick CLI and configs.
- Efficiency boosts via Unsloth and PEFT make big models feasible on modest hardware.
- Standardization helps, but algorithm wars and data issues persist—don't drink the full hype kool-aid.
🧠 What's your take on this?
Cast your vote and see what theAIcatchup readers think
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by MarkTechPost
Related Stories

AI Hardware
Arcee AI's 400B Sparse MoE Cracks Open Agentic AI — #2 on PinchBench, Just Behind Claude

AI Hardware
Screenshot-Seeking AI Agents: The Desktop Automation Savior That Actually Delivers

AI Hardware
Local AI Judged My WhatsApp Friends—And Exposed How Shallow We All Are

AI Hardware