VLAs: Robots That See, Talk, and (Sorta) Act – The Hype Meets Reality
A humanoid bot grabs your coffee mug after you say 'pick it up' – smooth, right? Wrong. Visual-Language-Action models promise robot revolution, but dig deeper and it's demos, not dollars.
⚡ Key Takeaways
- VLAs fuse vision, language, and actions via transformer backbones and imitation learning, but rely heavily on human teleop data. 𝕏
- Latent representations are core, echoing brain theories, yet real-world scaling remains a cash-burning hurdle. 𝕏
- Skeptical outlook: Big demos, little money – echoes past AI hype cycles like self-driving promises. 𝕏
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by Towards Data Science
Related Stories

Robotics
NXP's Blueprint: Squishing Robot AI Brains into Phone-Sized Chips

Robotics
NVIDIA's Dynamo Ignites Agentic AI Factories — While Bezos Bets $100B on Robot Factories
Robotics
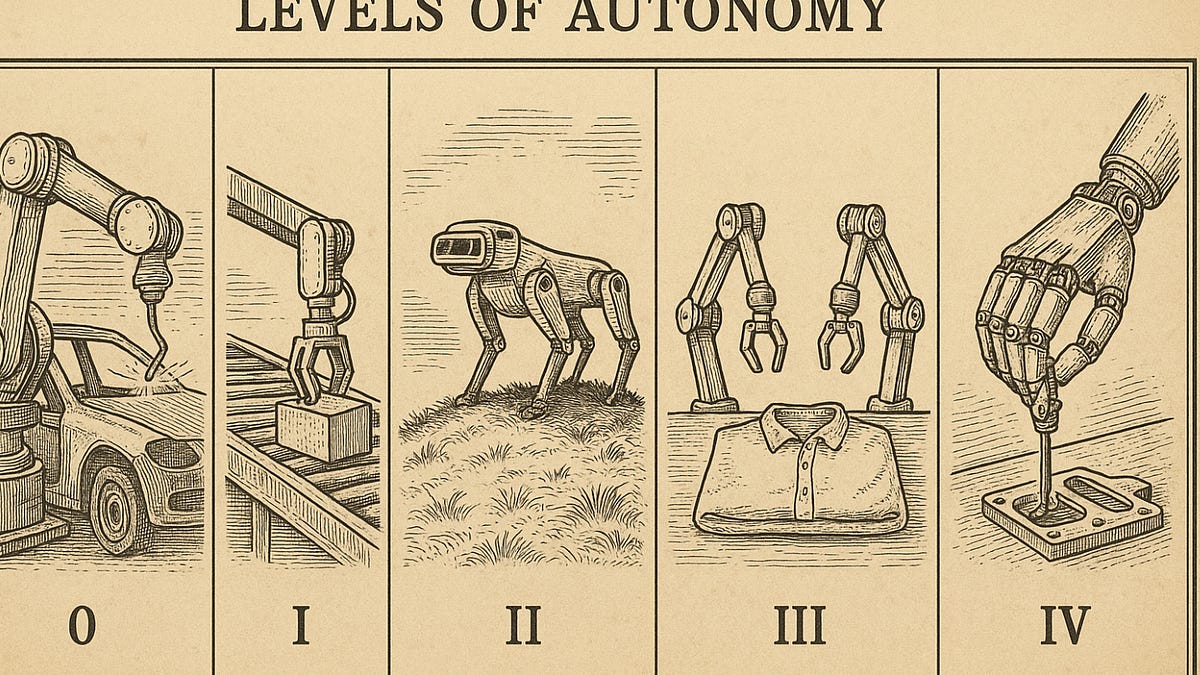
Robotics Levels of Autonomy: The Roadmap from Factory Drudge to Job-Snatching Shapeshifter
Robotics