So, the latest buzzword making the rounds is ‘knowledge bases for AI models.’ Sounds fancy, right? Like we’re finally teaching these glorified calculators to, you know, know things. I’ve spent two decades watching Silicon Valley chase the next shiny object, and let me tell you, this one’s got all the hallmarks of a familiar song and dance.
Look, the promise is simple: feed your AI a curated pile of information, and it’ll spit out smarter, more accurate answers. No more hallucinating about the company’s return policy or inventing features that don’t exist. The original article lays out a six-step plan to get there, and on paper, it looks clean. Collect data, clean it, chunk it, index it, store it. Simple enough. But here’s the kicker: who’s actually making money here, and are we just building ever-more-complex digital filing cabinets that are still fundamentally flawed?
The Data Deluge: More Really Isn’t Better
The first step, ‘collect data,’ is where the shiny veneer starts to crack. The advice? Prioritize value over volume. Brilliant. Except, for years, the prevailing wisdom in machine learning was ‘more data is always good.’ Now we’re told to be discerning. It’s a classic case of ‘garbage in, garbage out,’ and the tech vendors selling you these systems are happy to take your data, valuable or not, and process it through their expensive pipelines. If you’re building a customer support bot, they say, you only need factual and tutorial content. Great advice, if you know exactly what constitutes ‘factual’ and ‘tutorial’ for your specific, unique business. Most companies don’t.
And this trend of feeding AI-generated data into these bases? A double-edged sword, they admit. Speed versus reliability. It’s like asking a student to write an essay using only other AI-generated essays. Sure, they’ll churn it out, but the substance—and the actual learning—is questionable at best. Who’s verifying this stuff? Probably not the folks building the AI models, who are too busy chasing the next funding round.
Chunking It Up: Breaking Down the Bricks
Cleaning and segmenting data into ‘chunks’ is the next hurdle. Removing duplicates, standardizing terminology – sounds like good old-fashioned data hygiene. But then you get to metadata and access control. Suddenly, your simple knowledge base is becoming a mini-database with its own security protocols. And the tip about chunking based on user queries rather than document structure? It sounds clever, but it implies you already know every conceivable user query. That’s a big assumption, one that often requires significant upfront investment in user research or, you guessed it, more data analysis.
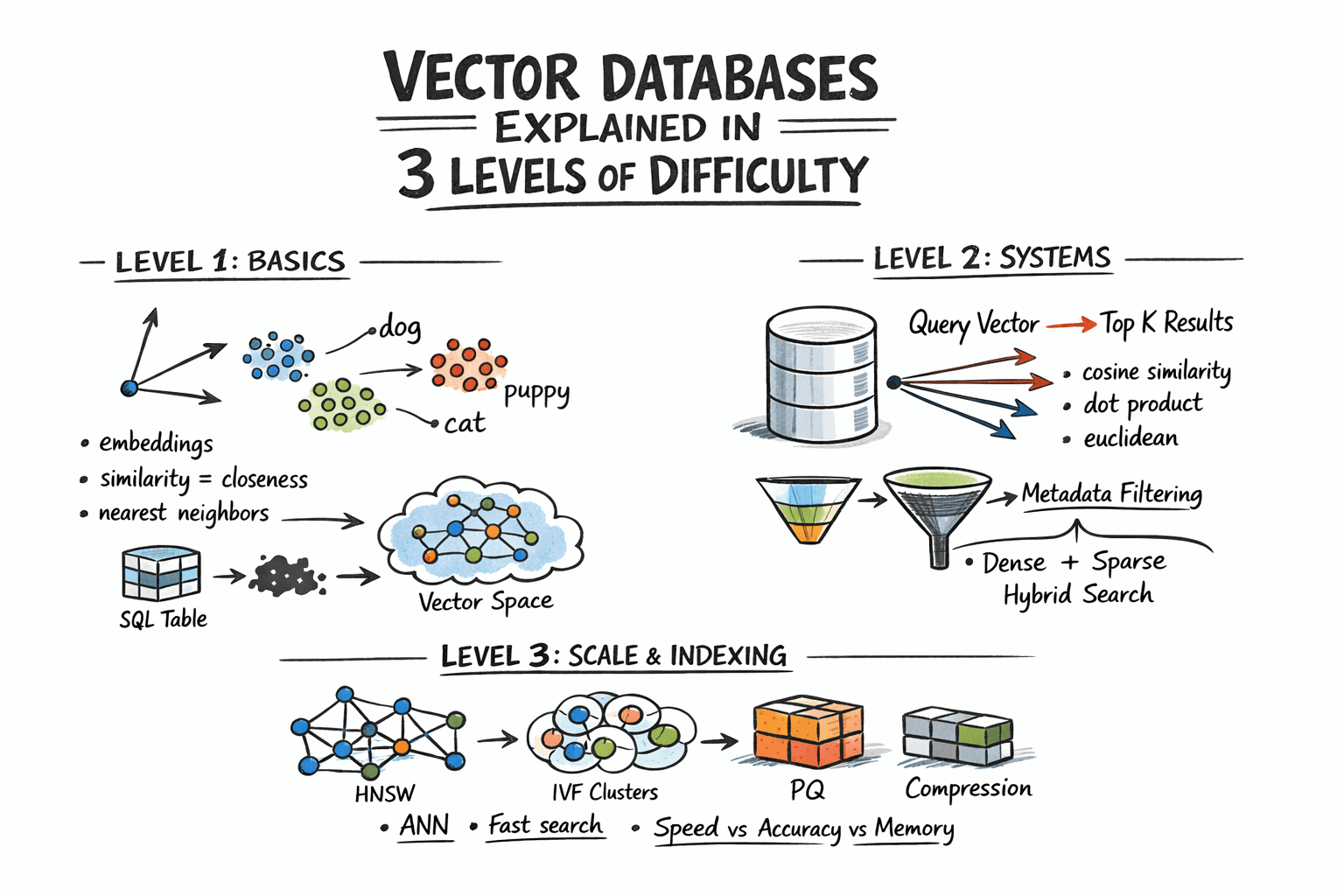
The Vector Vector Vector
Then comes the real magic trick: converting text into vectors. These are just numbers, mind you, representing your data in a mathematical space. AI models can supposedly ‘skim’ these vectors faster. The end result? [Vector (numbers)] + [Original text] + [Metadata]. It’s a neat package, but what’s actually happening under the hood? We’re taking human language, reducing it to numerical representations, and hoping the AI can infer meaning without the nuance and context that humans naturally grasp. It’s like trying to understand a symphony by looking at the sheet music without ever hearing the music itself. The potential for misinterpretation is astronomical.
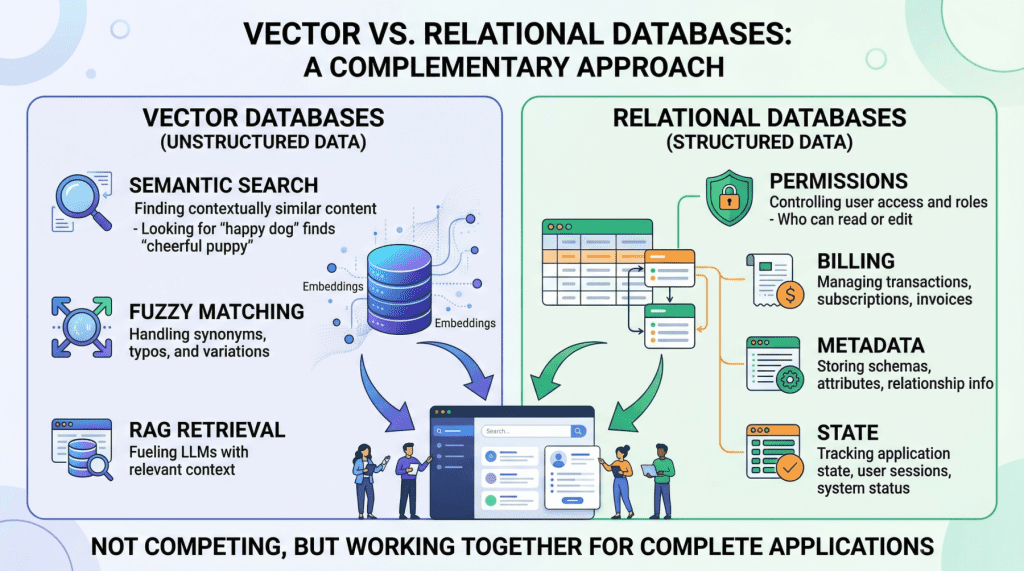
Where Does the Data Live?
Finally, you need a ‘platform to store data.’ The article lists vector databases like Pinecone, Milvus, or Weaviate. These aren’t your grandpa’s SQL databases. They’re specialized, often proprietary, and can get expensive quickly. You’re not just building a knowledge base; you’re signing up for another vendor lock-in, another subscription service to manage. And that Python code snippet they provide? It’s a basic example, sure, but integrating this into a production environment—with error handling, scalability, and security—is a whole different ballgame. It’s not just about uploading data; it’s about building and maintaining a complex infrastructure.
This whole process strikes me as an elaborate way to manage what’s essentially a very sophisticated FAQ. Are we truly building ‘knowledge’ or just incredibly detailed, searchable instruction manuals? The real question isn’t how to build a knowledge base, but why we need such a complex edifice for tasks that, frankly, a well-organized human team could handle with less fuss and far more genuine understanding.
Is This Just a Sophisticated FAQ?
The core of building an efficient knowledge base for AI models boils down to organizing and retrieving information effectively. The techniques described—data collection, cleaning, chunking, vectorization, and storage in vector databases—are designed to make vast amounts of data accessible and digestible for AI. However, the complexity and cost involved often raise questions about whether the outcome justifies the investment for many organizations, especially when compared to simpler, more human-managed information systems.
Who’s Really Benefiting From This?
Let’s be blunt: the primary beneficiaries of this ‘knowledge base’ trend are the companies selling the tools and infrastructure. Vector database providers, AI platform vendors, and consultancies offering to set all this up are raking in the dough. For businesses, the ROI is often murky. They invest heavily in data collection, cleaning, and specialized databases, only to find that their AI still struggles with nuanced queries or requires constant retraining. It’s a cycle of dependency, where the ‘solution’ creates more complexity and a perpetual need for more specialized tools and expertise. It’s a cash cow, alright, but who’s getting milked?
“Prioritize value over volume and collect all data that is relevant for your model. It could be in the form of: Factual and tutorial content, problem-solving content, historical data, real-time data, domain data.”
This quote, buried deep in the article, perfectly encapsulates the challenge. ‘Relevant’ is subjective. ‘Value’ is difficult to quantify. The burden of defining and curating this ‘relevant’ and ‘valuable’ data falls squarely on the organization implementing the AI. It’s a monumental task that requires deep domain expertise, which, ironically, is exactly what the AI is supposed to augment or replace. It feels like we’re building a very expensive, very complicated library, only to ask the AI to read the Dewey Decimal System. The AI should be able to understand information, not just be fed catalog numbers.
Historical Echoes
This reminds me of the early days of cloud computing. Vendors promised massive cost savings and scalability, and for some, it delivered. But many companies got locked into expensive, complex cloud infrastructures, only to find that managing their cloud spend and ensuring data security was a constant headache. This AI knowledge base push feels eerily similar. We’re being sold a sophisticated, yet fundamentally brittle, system that requires ongoing investment and expertise, all to achieve what? Better answers from a machine that’s still, at its core, a probabilistic model.
Ultimately, while the technical steps are laid out, the human element—the critical thinking, the domain expertise, the actual understanding of the information—is what’s missing from the purely technical pipeline. And until we address that gap, these ‘knowledge bases’ will remain sophisticated paperweights, useful for very narrow tasks, but far from true artificial intelligence.
🧬 Related Insights
- Read more: macOS Privacy Settings Just Got Exposed: They Don’t Actually Block App Access
- Read more: Thursday’s Linux Patch Onslaught: OpenSSL, Kernels, Firefox Under Fire
Frequently Asked Questions
What is a knowledge base for AI models? A knowledge base for AI models is a curated collection of data, structured and organized to provide an AI system with specific information, context, and facts to improve its accuracy and relevance in generating responses or performing tasks.
How do I clean data for an AI knowledge base? Cleaning data involves removing duplicates and outdated information, deleting irrelevant details (like headers/footers), and standardizing content for consistent terminology and format before feeding it into the AI model.
Will building an AI knowledge base replace human experts? While an AI knowledge base can augment and assist human experts by providing quick access to information and automating certain tasks, it’s unlikely to fully replace human expertise, which involves critical thinking, creativity, and nuanced judgment.