Nvidia's $20B Groq Gambit: SRAM Inferno Torches GPU-Only Inference
Nvidia just folded a startup's wild SRAM accelerator into its crown-jewel Rubin platform. Forget pure GPU racks; here's why inference is going hybrid, fast.
⚡ Key Takeaways
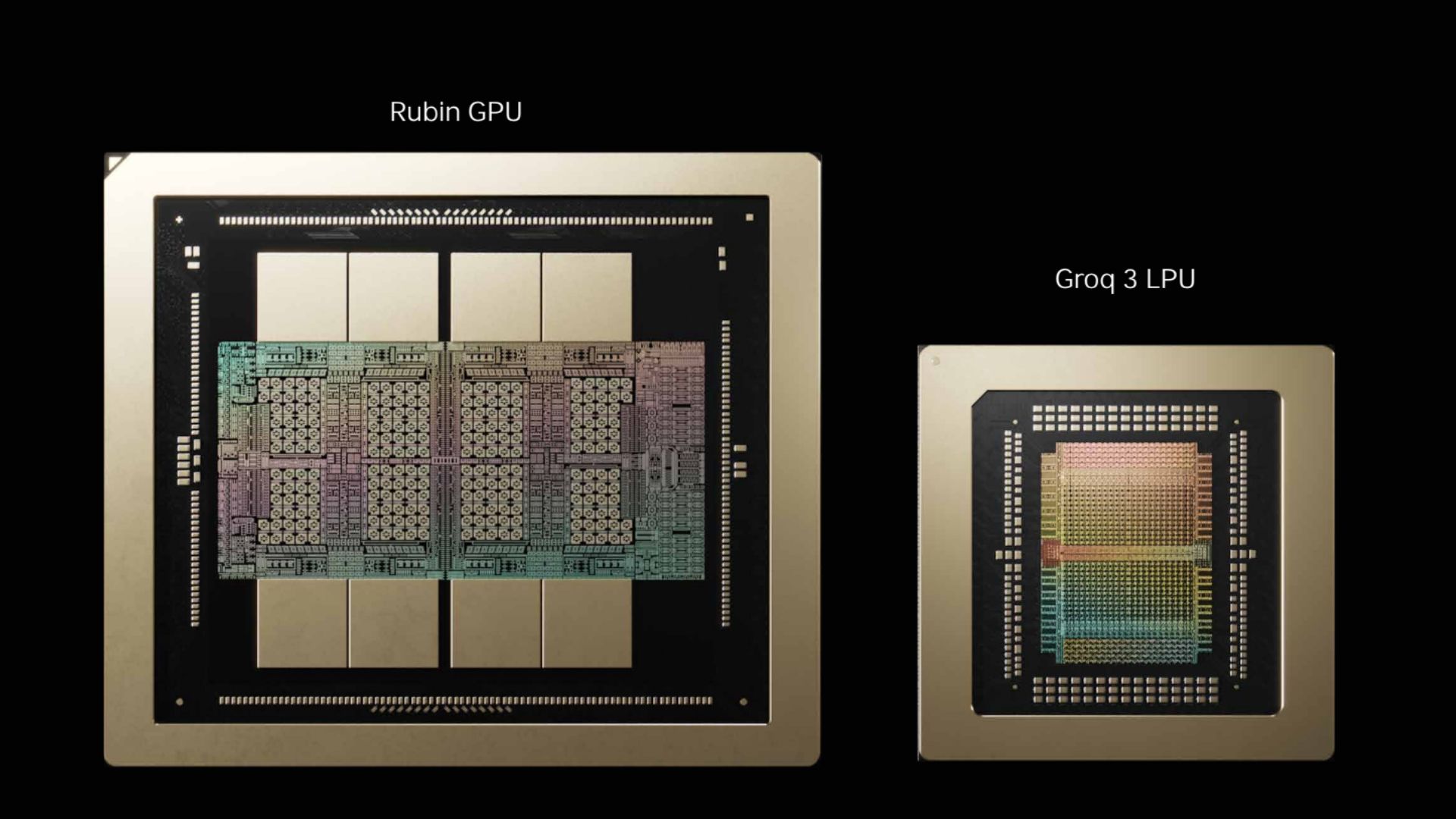
- Nvidia's $20B Groq deal integrates SRAM LPUs into Rubin, axing CPX for hybrid inference racks.
- Groq 3 delivers 40 PB/s rack bandwidth, 35x better efficiency than GPU-only for decode.
- Startup consolidation wave cements Nvidia's inference moat via Dynamo orchestration.
🧠 What's your take on this?
Cast your vote and see what theAIcatchup readers think
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by Tom's Hardware - AI
Related Stories

AI Hardware
Arcee AI's 400B Sparse MoE Cracks Open Agentic AI — #2 on PinchBench, Just Behind Claude

AI Hardware
Screenshot-Seeking AI Agents: The Desktop Automation Savior That Actually Delivers

AI Hardware
Local AI Judged My WhatsApp Friends—And Exposed How Shallow We All Are

AI Hardware