Inference Scaling: LLMs' Desperate Bid for Smarter Outputs
LLMs can't reason? No problem—just throw more compute at inference time. But is this scaling wizardry or just expensive guesswork?
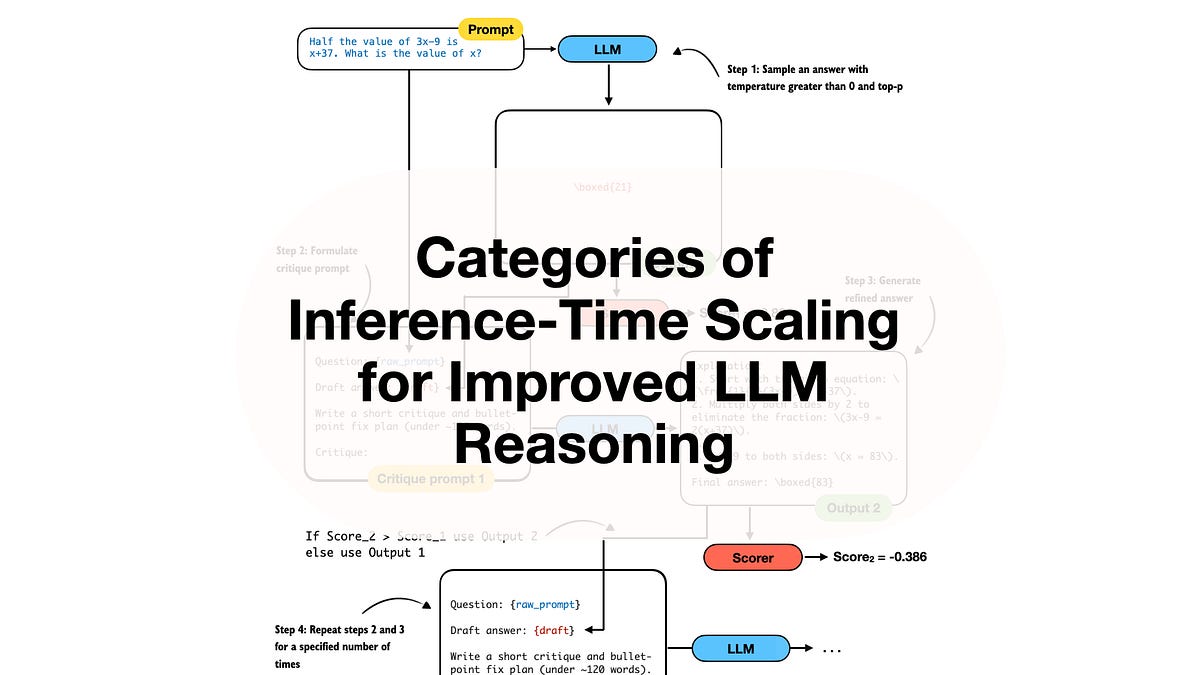
⚡ Key Takeaways
- Inference scaling boosts LLMs via extra runtime compute, but it's no substitute for real reasoning.
- Key categories: prompting tricks, sampling/ranking, self-refinement, and path search.
- Diminishing returns loom; it's a temporary patch echoing 90s ML ensembles.
🧠 What's your take on this?
Cast your vote and see what theAIcatchup readers think
Worth sharing?
Get the best AI stories of the week in your inbox — no noise, no spam.
Originally reported by Ahead of AI
Related Stories

AI Hardware
Arcee AI's 400B Sparse MoE Cracks Open Agentic AI — #2 on PinchBench, Just Behind Claude

AI Hardware
Screenshot-Seeking AI Agents: The Desktop Automation Savior That Actually Delivers

AI Hardware
Local AI Judged My WhatsApp Friends—And Exposed How Shallow We All Are

AI Hardware